RecurrentGemma de Google integra inteligencia artificial avanzada en lenguaje para mejorar el rendimiento de dispositivos en la edge.
Most people like
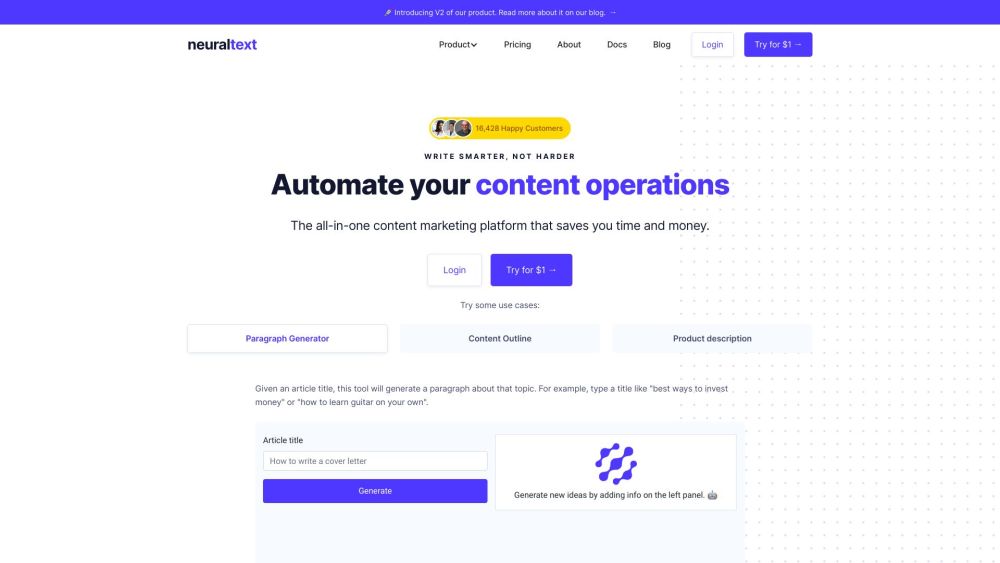
En la era digital, crear contenido de alta calidad es esencial para la visibilidad y el compromiso en línea. Los asistentes de escritura por IA y las herramientas de SEO están revolucionando la forma en que producimos textos, facilitando la creación de narrativas atractivas que resuenan con las audiencias. Estas tecnologías avanzadas no solo mejoran la eficiencia de la escritura, sino que también optimizan el contenido para los motores de búsqueda, asegurando que tu trabajo llegue al público deseado. Al aprovechar el poder de la IA y el SEO, los escritores pueden elevar su estrategia de contenido, mejorar su clasificación en búsquedas y, en última instancia, atraer más tráfico a sus sitios web. Descubre cómo estas herramientas innovadoras pueden transformar tu proceso de escritura y amplificar tu presencia en línea.
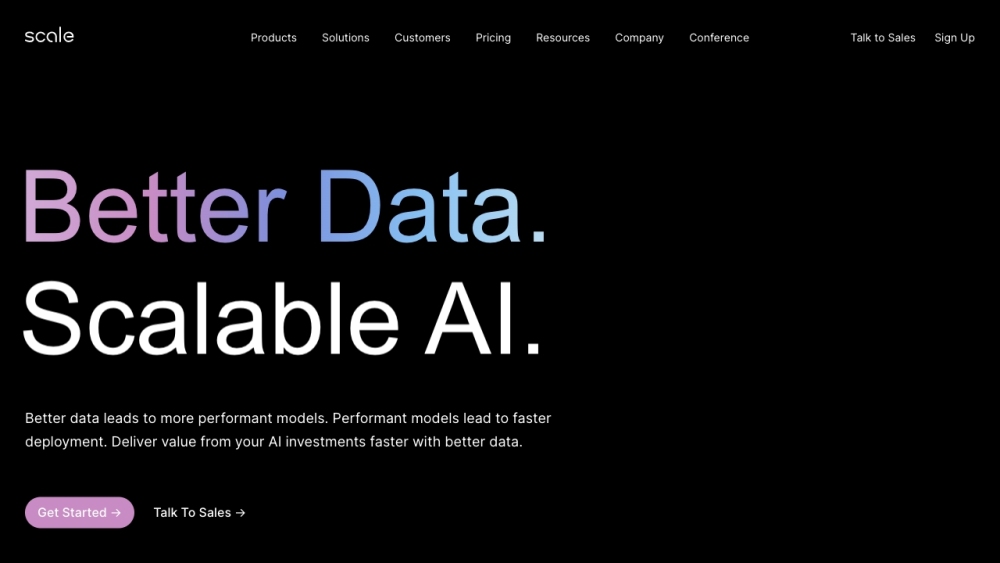
Scale AI proporciona datos de entrenamiento confiables y de alta calidad, adaptados a una amplia gama de aplicaciones de inteligencia artificial. Nuestras soluciones permiten a las empresas mejorar sus modelos de aprendizaje automático e impulsar la innovación en el dinámico panorama de la inteligencia artificial.
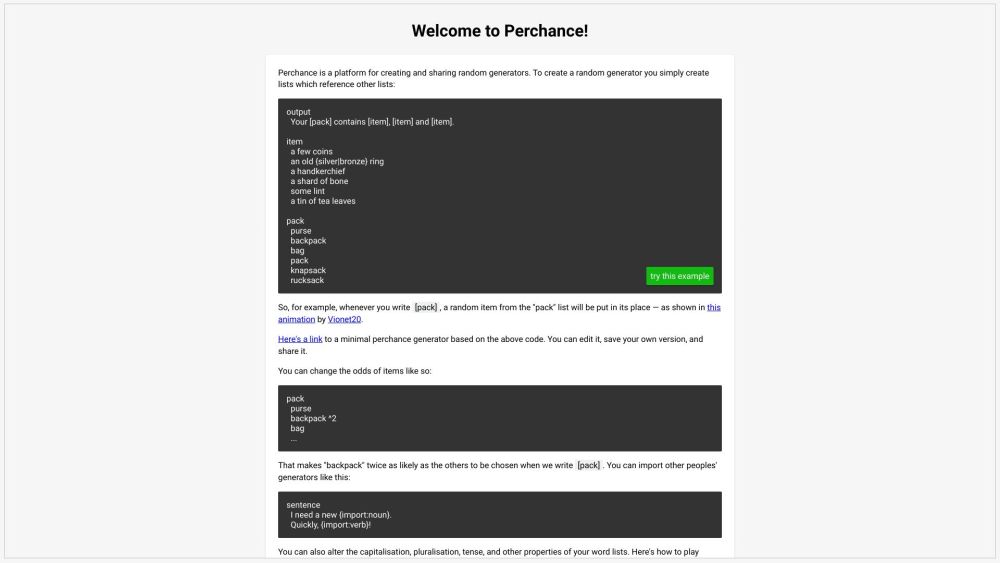
Descubre una plataforma innovadora diseñada para crear generadores aleatorios sin esfuerzo. Esta herramienta versátil permite a los usuarios diseñar generadores personalizados para una amplia gama de aplicaciones, desde juegos y toma de decisiones hasta la lluvia de ideas y la narración creativa. Ya seas desarrollador, educador o un entusiasta creativo, esta plataforma te capacita para crear soluciones de aleatorización originales que cautiven e inspiren. ¡Desbloquea tu creatividad hoy con la plataforma definitiva para crear generadores de aleatoriedad!
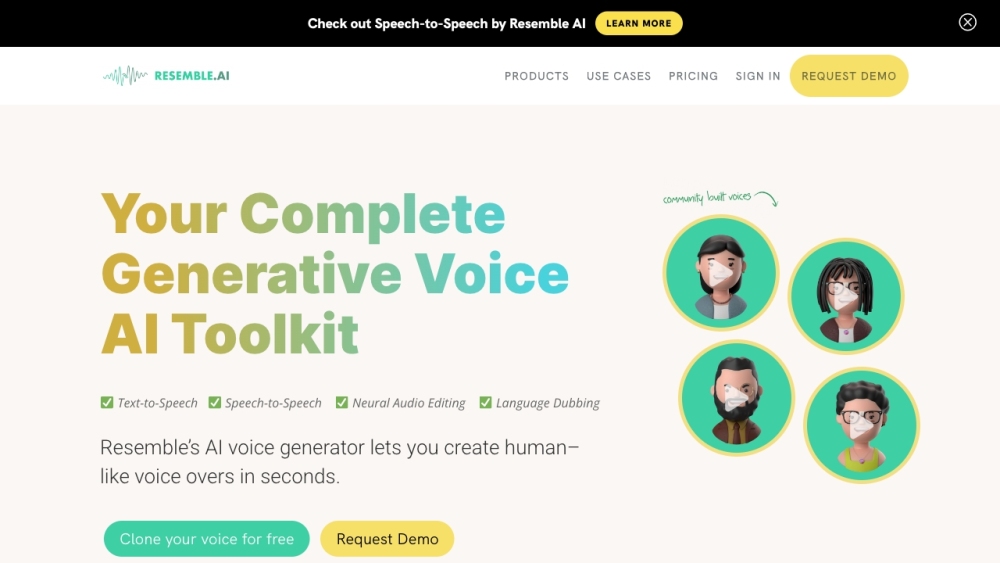
Crea voces sintéticas realistas en solo segundos. Experimenta el poder de la tecnología de vanguardia que ofrece soluciones de audio realistas adaptadas a tus necesidades.
Find AI tools in YBX
Related Articles
Refresh Articles