Zyphra Lanza Zyda: un Conjunto de Datos de Modelado de Lenguaje de 1.3T que Asegura Superar a Pile, C4 y arXiv
Most people like
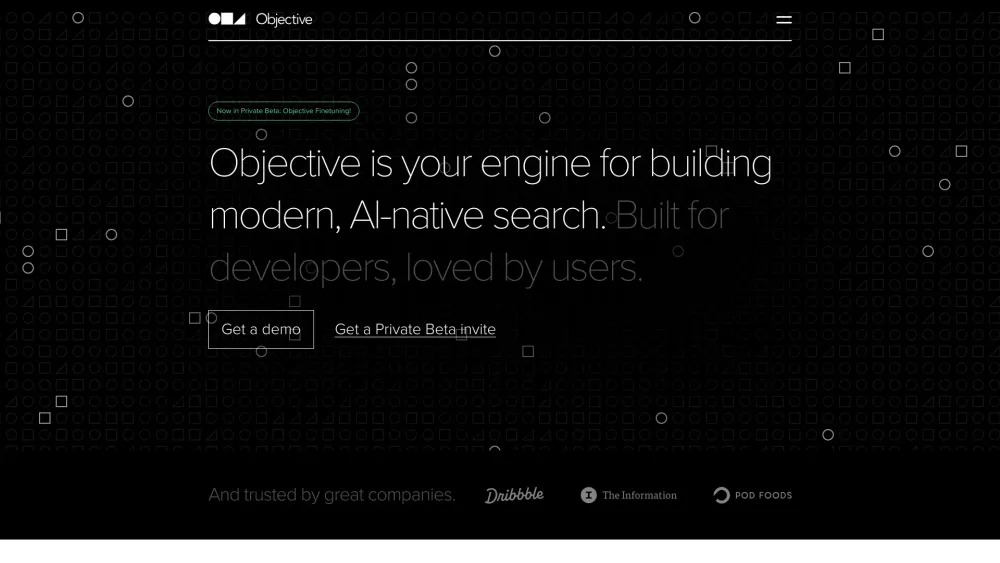
Presentamos nuestra API de Búsqueda nativa de IA, diseñada específicamente para aplicaciones web y móviles. Mejora la experiencia de tus usuarios con funcionalidades de búsqueda de vanguardia que aprovechan la inteligencia artificial para ofrecer resultados altamente relevantes. Nuestra API optimiza la eficiencia de búsqueda, garantizando una integración fluida y un mayor compromiso en tus aplicaciones. ¡Desbloquea el poder de las capacidades de búsqueda inteligente hoy mismo!
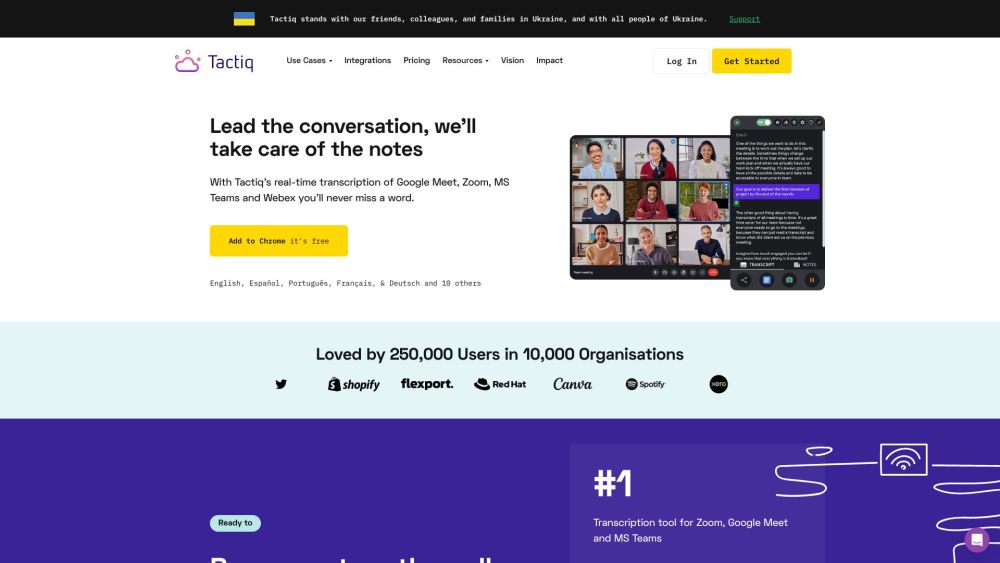
Tactiq es una herramienta de transcripción excepcional diseñada específicamente para reuniones en línea, que ofrece transcripción en tiempo real y resúmenes concisos de las reuniones. Aumenta tu productividad y mejora la colaboración con Tactiq, la solución ideal para capturar y organizar tus discusiones virtuales de manera efectiva.
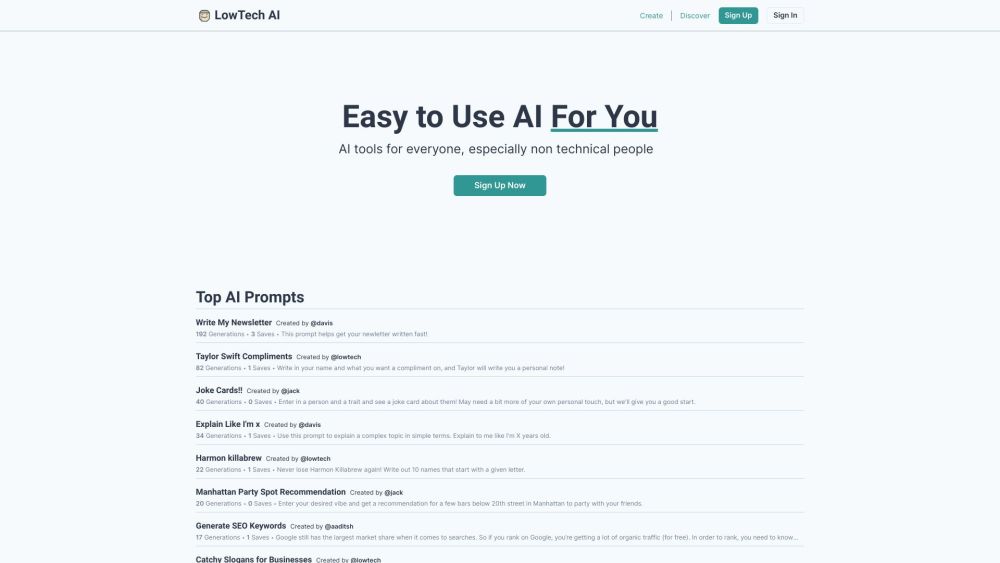
Descubre una plataforma de IA intuitiva diseñada específicamente para usuarios sin conocimientos técnicos, con potentes sugerencias adaptadas para profesionales.
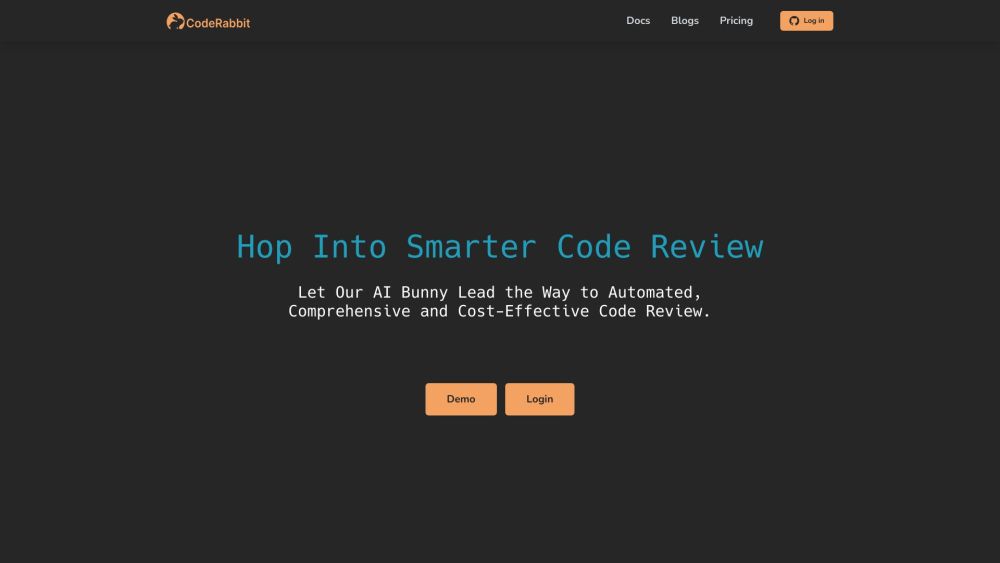
CodeRabbit es una herramienta innovadora de inteligencia artificial diseñada para acelerar las revisiones de código al proporcionar valiosos conocimientos impulsados por IA.
Find AI tools in YBX
