Combatiendo la desinformación de chatbots: Google DeepMind y la Universidad de Stanford presentan una herramienta de verificación de hechos con IA.
Most people like
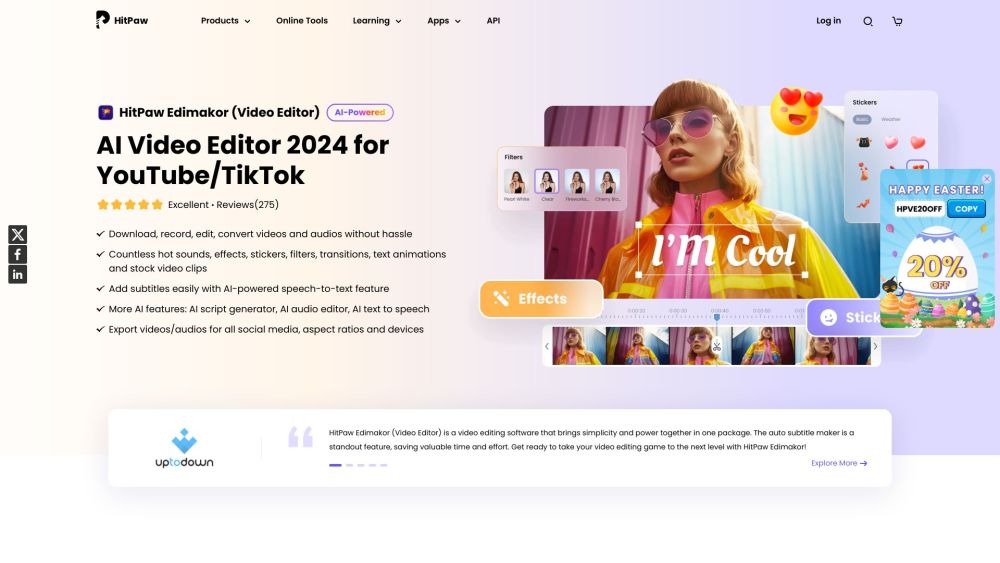
Presentamos un editor de video con inteligencia artificial, equipado con características de vanguardia que mejoran tu experiencia de producción de video. Esta herramienta innovadora aprovecha el poder de la inteligencia artificial para simplificar el proceso de edición, permitiéndote crear videos impresionantes sin esfuerzo. Ya seas creador de contenido, comercializador o cineasta, nuestro avanzado editor de video simplifica tareas complejas y mejora tus capacidades de edición, permitiéndote enfocarte en contar tu historia. Descubre el futuro de la edición de video y transforma tu visión creativa en realidad.
Las plataformas de contenido y chat basadas en inteligencia artificial están revolucionando la forma en que las empresas interactúan con sus clientes. Al aprovechar la avanzada tecnología de inteligencia artificial, estas plataformas facilitan una comunicación fluida, mejoran el engagement del usuario y optimizan la creación de contenido. A medida que las organizaciones dependen cada vez más de soluciones digitales para mejorar las experiencias del cliente y aumentar la eficiencia, entender las capacidades y beneficios de las herramientas impulsadas por inteligencia artificial se ha vuelto esencial. Descubre cómo estas tecnologías innovadoras no solo transforman el servicio al cliente, sino que también redefinen la entrega de contenido en el panorama digital.

Bienvenido a nuestra plataforma de insights de IA, diseñada específicamente para creadores y empresas que buscan aprovechar el poder de la inteligencia artificial. Nuestra plataforma ofrece valiosos insights basados en datos que empoderan a los usuarios para mejorar la creatividad, optimizar la toma de decisiones y fomentar el crecimiento. Descubre cómo la IA puede transformar tus proyectos y estrategias, allanando el camino hacia el éxito en el competitivo panorama actual. ¡Explora nuestras características para desbloquear tu máximo potencial!

Soluciones revolucionarias para el cuidado de la piel y el cabello, diseñadas específicamente para el antienvejecimiento. Descubre cómo formulaciones inteligentes pueden ayudarte a lograr una piel joven y radiante, así como un cabello vibrante.
Find AI tools in YBX
Related Articles
Refresh Articles