Apple, NVIDIA et Anthropic auraient utilisé des transcriptions YouTube sans consentement pour entraîner leurs modèles d'IA.
Most people like
Dans le paysage juridique moderne, l'efficacité de la recherche juridique est primordiale. Notre plateforme révolutionne la manière dont les professionnels du droit recherchent et analysent des documents, offrant des fonctionnalités intuitives et des algorithmes avancés qui simplifient le processus. Grâce à nos outils sophistiqués, les utilisateurs peuvent localiser sans effort des documents juridiques pertinents, obtenir des analyses approfondies et améliorer leur productivité globale. Découvrez une nouvelle ère de la recherche juridique qui permet aux praticiens du droit de prendre des décisions éclairées avec aisance.
SEO Bot est une plateforme alimentée par l'IA pour les entrepreneurs occupés, prenant en charge vos besoins en SEO et en blogging, vous permettant ainsi de libérer du temps pour vous concentrer sur votre activité principale.
Contournez facilement les outils de détection avancés de l'IA en créant un contenu généré par l'IA qui est fiable et indétectable.
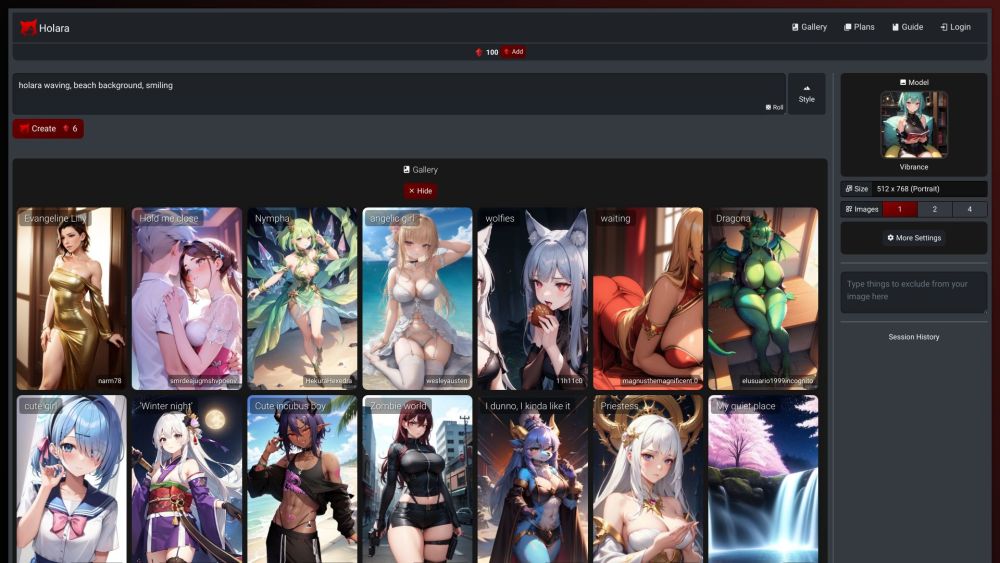
Êtes-vous un passionné d'anime ou un artiste en herbe désireux de donner vie à vos visions créatives ? Notre plateforme IA de pointe propose une manière novatrice de générer des œuvres d'art anime époustouflantes sans effort. Grâce à une interface conviviale et des algorithmes avancés, vous pouvez transformer vos idées en visuels saisissants en un rien de temps. Rejoignez une communauté de créateurs et libérez votre imagination avec nos outils puissants spécifiquement conçus pour l'art anime. Embrassez l'avenir de la créativité avec notre plateforme alimentée par l'IA dès aujourd'hui !
Find AI tools in YBX
