Déchaîner GPT-4 : Performances Éblouissantes dans l'Évaluation Ophtalmique et Recommandations d'Experts pour une Mise en Œuvre Prudente
Most people like

Libérez le potentiel de votre eCommerce avec AdCopy.ai, une plateforme innovante alimentée par l'IA qui vous aide à créer facilement des textes publicitaires accrocheurs. Améliorez votre stratégie marketing et augmentez vos conversions grâce à un contenu expert généré sur mesure pour votre audience.

Explorez et créez facilement de la musique générée par IA. Libérez votre créativité grâce à des outils innovants conçus pour les amoureux de la musique et les producteurs, vous permettant de découvrir des sons uniques qui transformeront votre expérience musicale. Plongez dans l'univers de l'intelligence artificielle et élevez vos compositions dès aujourd'hui !
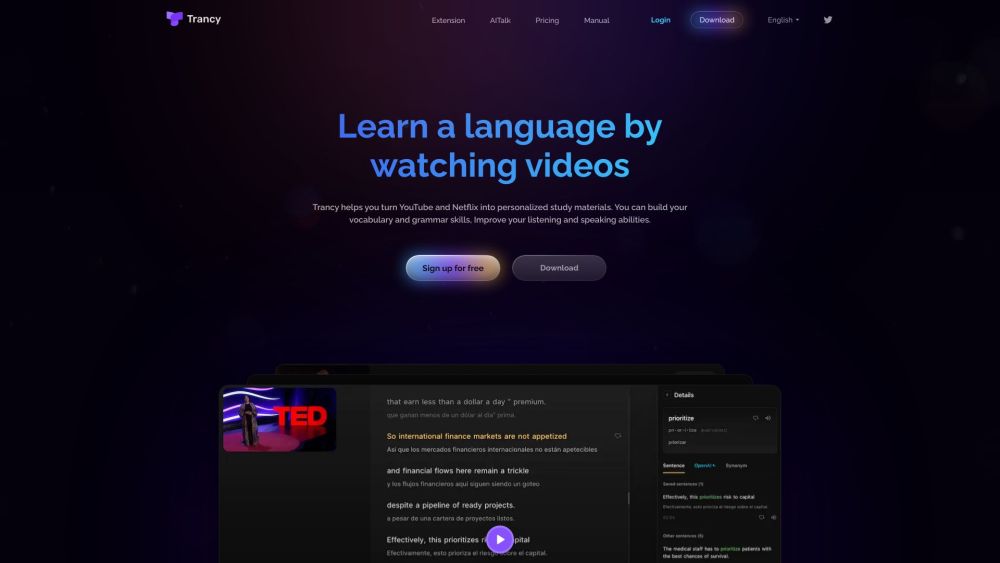
Découvrez comment apprendre des langues efficacement en regardant YouTube et Netflix avec Trancy, améliorant vos compétences de manière pratique et engageante.
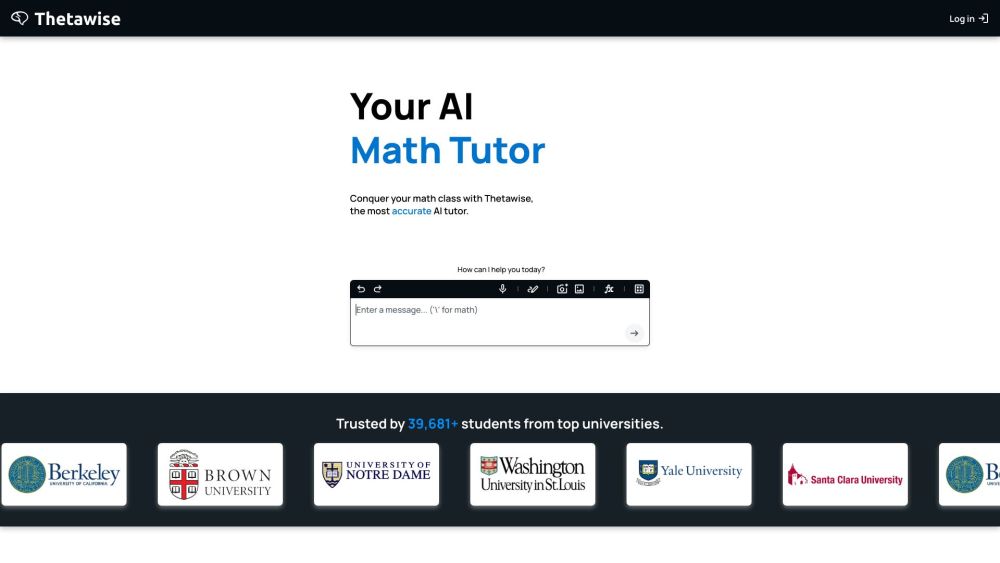
Découvrez les avantages du tutorat en mathématiques soutenu par l'IA, une approche novatrice conçue pour améliorer l'apprentissage et la compréhension des mathématiques. En s'appuyant sur des technologies avancées, ces systèmes intelligents offrent un soutien personnalisé, adapté aux styles et rythmes d'apprentissage individuels. Que vous ayez des difficultés avec l'algèbre, la géométrie ou le calcul avancé, les tuteurs en mathématiques alimentés par l'IA peuvent transformer votre expérience éducative, la rendant plus efficace et performante. Adoptez l'avenir de l'apprentissage avec des solutions pilotées par l'IA pour de meilleures compétences en mathématiques !
Find AI tools in YBX
Related Articles
Refresh Articles