OpenAI accusée de prélèvement non autorisé de vidéos YouTube pour entraîner le modèle IA Sora : un débat controversé émerge.
Most people like
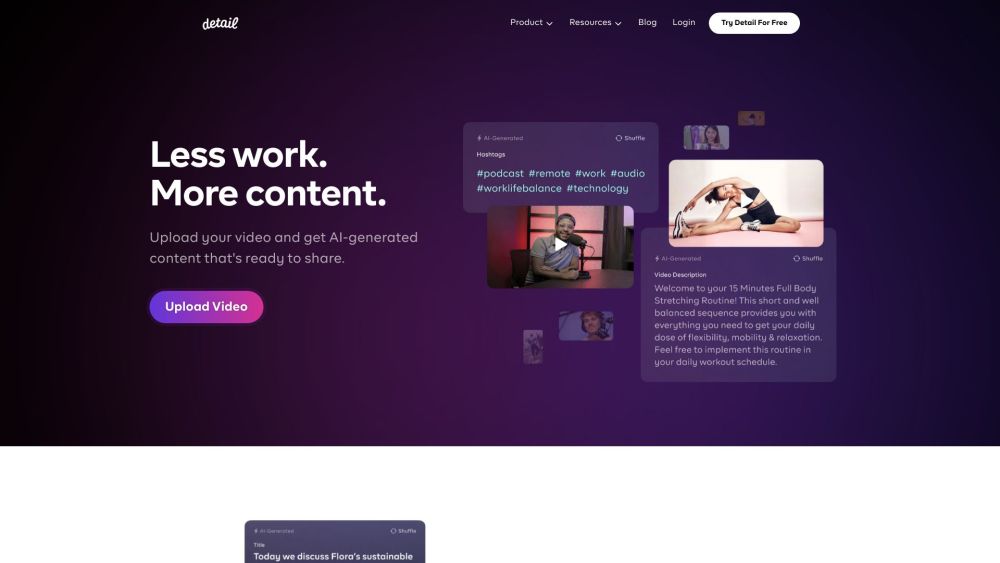
Detail est une application de caméra innovante conçue pour simplifier l'enregistrement et le montage vidéo pour les narrateurs en herbe. Grâce à son interface conviviale et à ses fonctionnalités puissantes, Detail permet aux utilisateurs de créer facilement des récits visuels captivants.
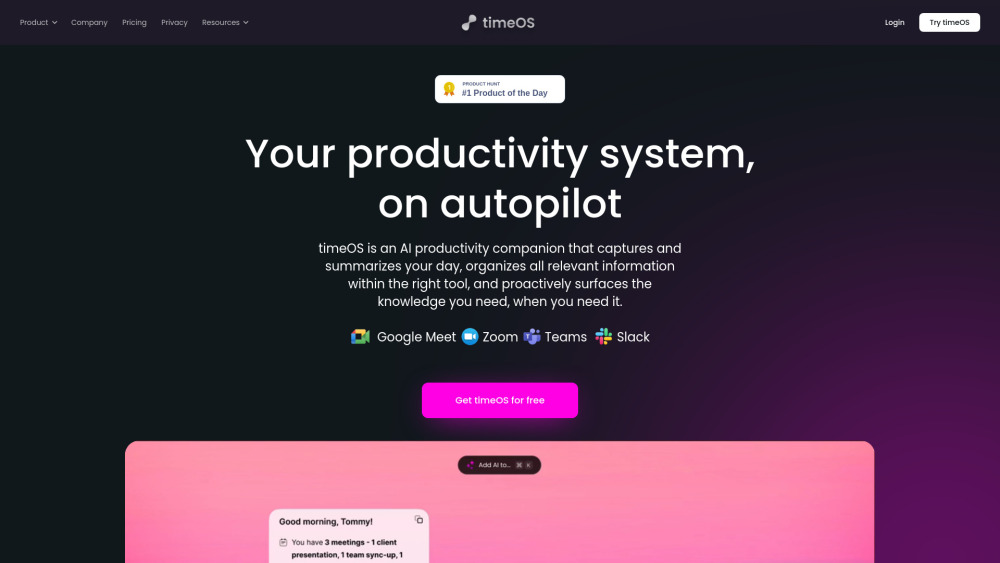
Présentation d'une Nouvelle Page d'onglet Alimentée par l'IA pour Optimiser la Préparation des Réunions
Améliorez votre productivité grâce à notre nouvelle page d'onglet innovante alimentée par l'IA, conçue spécifiquement pour améliorer votre expérience de préparation aux réunions. Avec des fonctionnalités intelligentes et une interface conviviale, cet outil vous aide à organiser vos informations, planifier vos discussions et accéder facilement aux ressources essentielles. Dites adieu aux notes désorganisées et à la planification inefficace — transformez votre flux de travail et faites en sorte que chaque réunion compte !
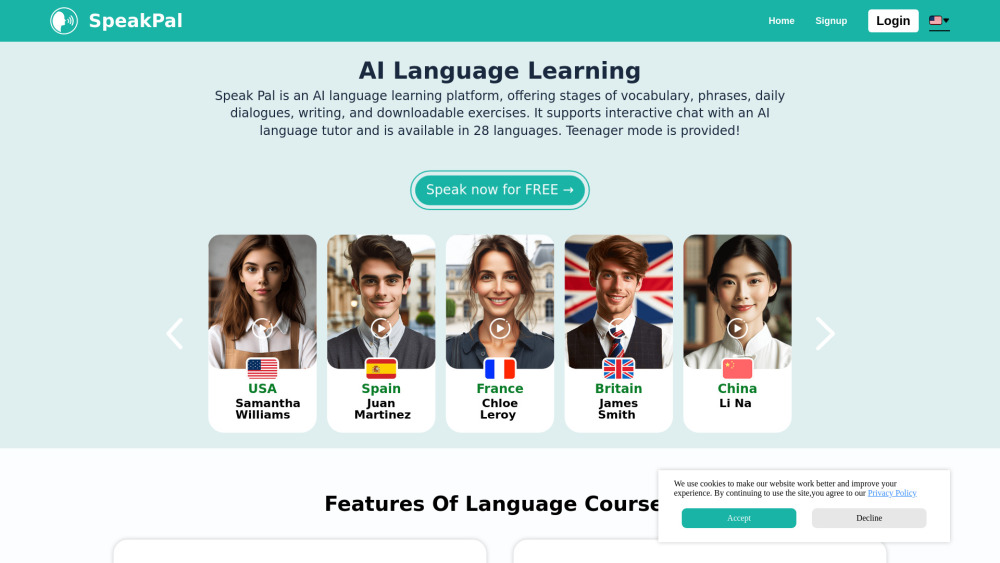
Découvrez une plateforme d'apprentissage linguistique alimentée par l'IA, dotée de capacités de chat interactif. Cet outil innovant enrichit votre parcours d'acquisition linguistique en offrant des conversations en temps réel, des retours personnalisés et des activités engageantes. Profitez d'un apprentissage fluide en pratiquant l'oral, l'écoute et l'écriture dans un environnement dynamique, adapté à vos objectifs uniques. Déverrouillez le monde de l'apprentissage des langues et élevez vos compétences sans effort grâce à notre fonctionnalité de chat interactif.
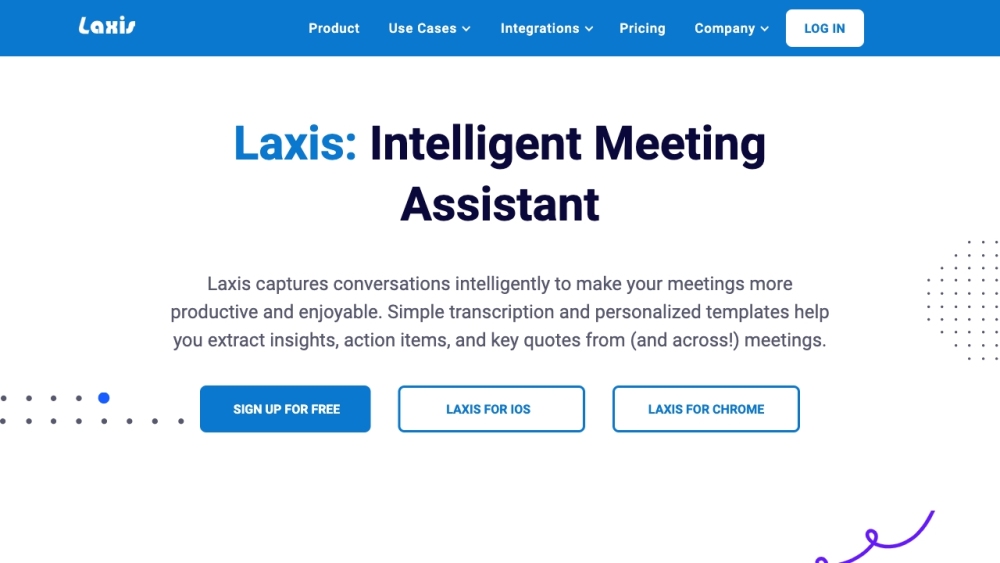
Laxis est un assistant de réunion IA avancé conçu pour capturer et transcrire les réunions de manière fluide, permettant aux équipes commerciales d'améliorer leur productivité et leur collaboration.
Find AI tools in YBX
Related Articles
Refresh Articles