Stability AI lance Stable Audio : une révolution pour les professionnels de la conception sonore.
Most people like
Diib est un outil SEO innovant conçu pour élaborer un plan de croissance personnalisé en analysant de manière fluide les données de votre site web en lien avec Google Analytics. En seulement 60 secondes, vous pouvez améliorer votre SEO, la vitesse de votre site, la sécurité et l'expérience utilisateur globale grâce à des recommandations claires et adaptées à vos besoins.
InVideo est une plateforme de montage vidéo en ligne puissante qui propose une large gamme de modèles premium, des images de haute qualité et une vaste bibliothèque musicale. Que vous créiez du contenu promotionnel, des vidéos pour les réseaux sociaux ou des projets personnels, InVideo vous offre les outils nécessaires pour améliorer vos vidéos et captiver efficacement votre audience.
Topic Mojo est un outil de recherche puissant conçu pour fournir des insights précieux aux créateurs de contenu, les aidant à élaborer un contenu engageant et pertinent. En s'appuyant sur une analyse approfondie des données, Topic Mojo permet aux utilisateurs de prendre des décisions éclairées qui améliorent leur processus de création de contenu.
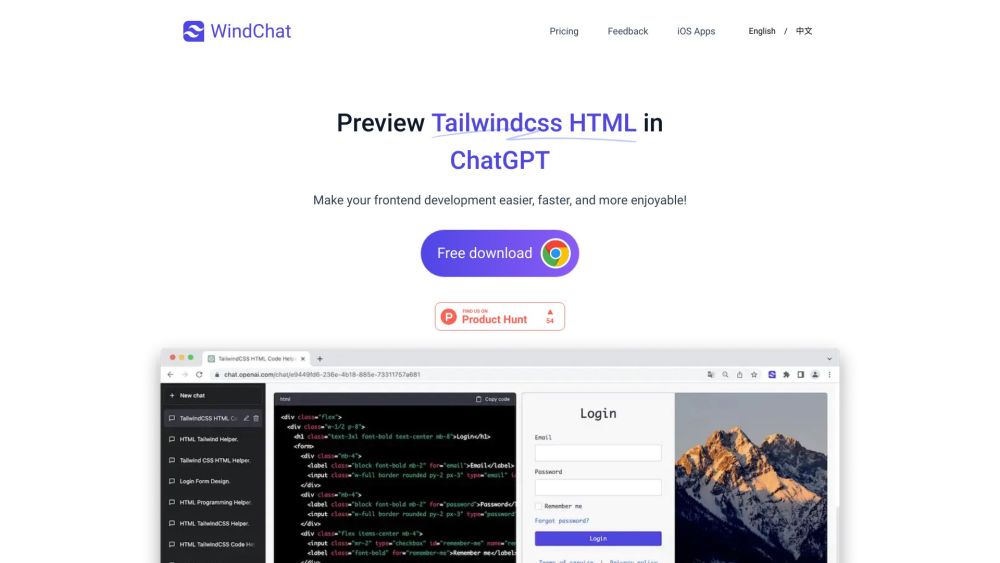
Découvrez comment prévisualiser sans effort le code HTML de Tailwind CSS directement dans ChatGPT. Améliorez votre expérience de conception web et optimisez votre flux de travail grâce à cette approche efficace. Que vous soyez débutant ou développeur expérimenté, ce guide vous aidera à tirer parti de la puissance de Tailwind CSS en parallèle avec ChatGPT pour une productivité et une créativité accrues. Plongez-y pour en savoir plus !
Find AI tools in YBX
Related Articles
Refresh Articles