Gemma 2 contre Llama 3 : Analyse complète des performances et des coûts des modèles linguistiques d'IA de nouvelle génération.
Most people like
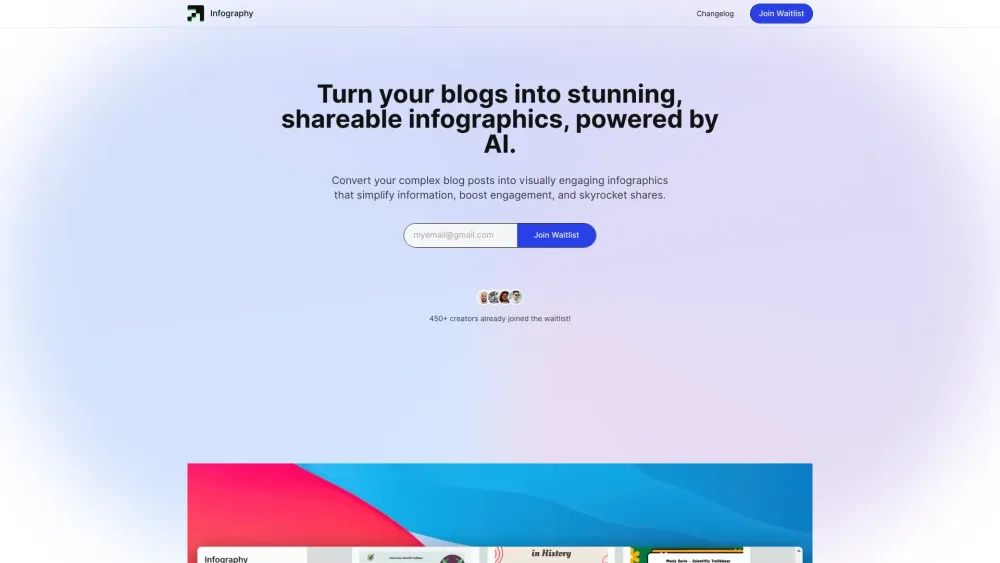
Cherchez-vous à améliorer le contenu de votre blog et à captiver votre audience ? Transformer vos articles en infographies accrocheuses est une méthode puissante pour présenter l'information de manière visuelle. Les infographies simplifient non seulement des données complexes, mais les rendent également plus partageables, augmentant ainsi la portée de votre contenu. Dans ce guide, nous explorerons des stratégies efficaces pour convertir votre contenu écrit en infographies époustouflantes qui engagent les lecteurs et rehaussent la visibilité de votre marque. Découvrez comment maximiser l'impact de vos articles de blog en exploitant l'art des infographies !
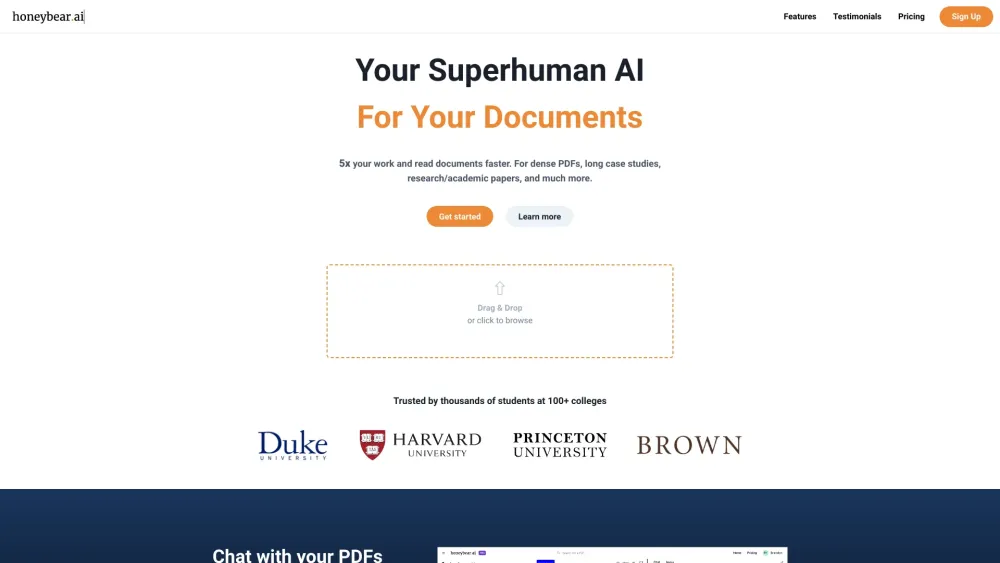
La navigation dans des PDF complexes peut être une tâche redoutable, que vous soyez étudiant confronté à des articles académiques ou professionnel gérant des rapports volumineux. Notre assistant IA est conçu pour simplifier cette expérience, facilitant l'extraction d'informations, la synthèse de contenu et l'amélioration de votre productivité. Découvrez comment notre outil novateur transforme votre interaction avec des documents PDF complexes, vous permettant ainsi de gagner du temps et d'améliorer votre compréhension. Adoptez l'avenir de la gestion documentaire avec notre solution alimentée par l'IA, adaptée à vos besoins.
Bienvenue sur NSFWChatAI.ai, la plateforme ultime de chatbot de petite amie virtuelle alimentée par l'IA, où vous pouvez engager des conversations sans aucune restriction avec votre compagnon virtuel. Découvrez la liberté de discuter sans limites dans un environnement sûr et interactif !
Find AI tools in YBX
Related Articles
Refresh Articles