AIの「コードレッド」から1年、GoogleのGeminiに寄せられた反発:避けられなかったのか?
Most people like
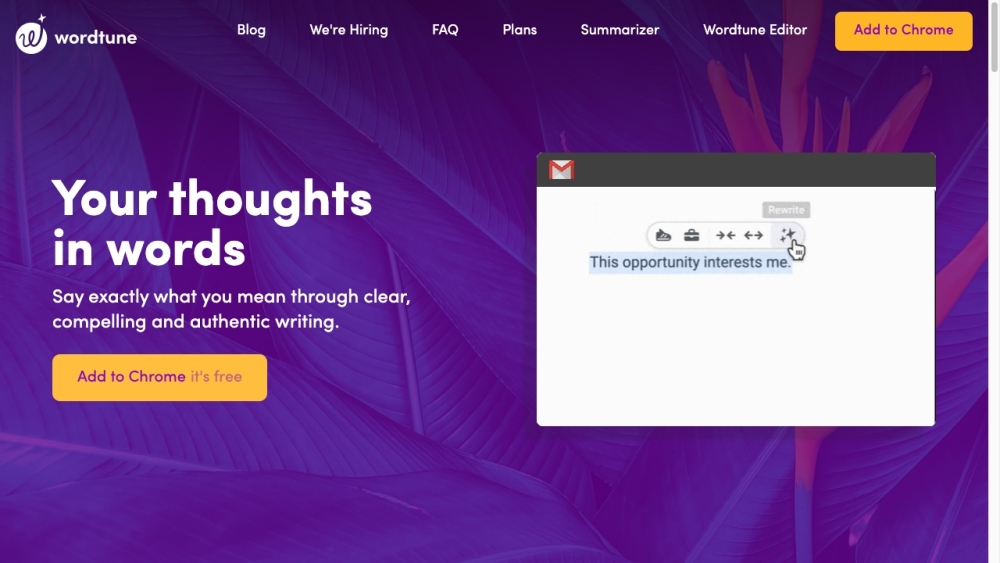
Wordtuneは、あなたのライティングを向上させるために設計されたインテリジェントなAIライティングアシスタントです。高度なアルゴリズムを用いて、Wordtuneはあなたの考えを明確かつ効果的に表現する手助けをします。
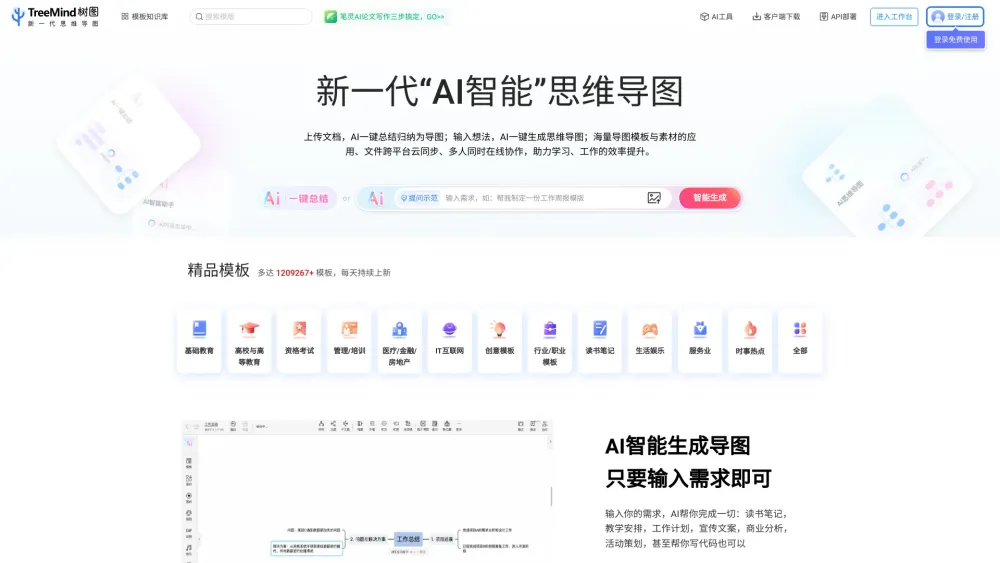
AIマインドマッピングソフトウェアの力を発見し、あなたの思考やアイデアを効果的に可視化しましょう。この革新的なツールは創造性を高め、生産性を向上させ、ブレインストーミングプロセスを効率化します。アイデアを整理し、発展させることが容易になります。マインドマッピングにおけるAIの変革的な影響を探求し、今すぐあなたの可能性を解放しましょう。
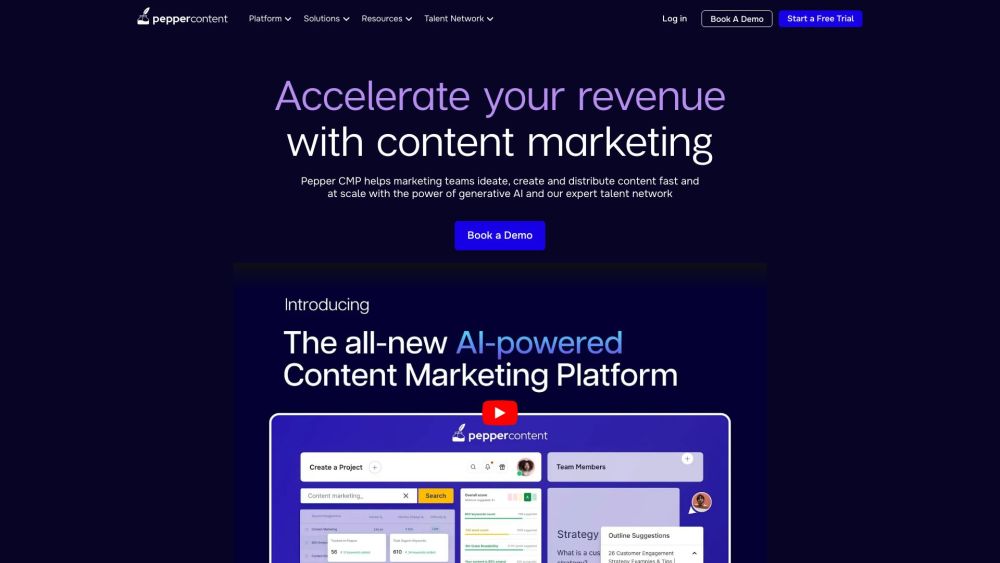
AI駆動のコンテンツマーケティングプラットフォームのご紹介
最先端のAI駆動型コンテンツマーケティングプラットフォームで、マーケティング戦略の可能性を引き出しましょう。コンテンツの作成と配信を効率化するよう設計された当プラットフォームは、人工知能の力を活用し、ターゲットオーディエンスに合わせた魅力的で関連性の高いコンテンツを提供します。顧客とのつながりを変革し、ブランドの認知度を高め、コンバージョンをスムーズに促進しましょう。今日、コンテンツマーケティングの未来を体験してください!

急速に進化する人工知能の分野において、大規模な中国語会話型言語モデルが革新の最前線に立っています。これらの高度なシステムは、人間のようなテキストを理解し生成するように設計されており、スムーズな中国語のコミュニケーションを可能にします。ビジネスや個人が効果的な情報共有や対話の方法を求める中、この技術はカスタマーサービスやコンテンツ作成などを変革しています。これらの強力なモデルがデジタル時代におけるコミュニケーションを向上させ、より深いつながりを育む方法をご覧ください。
Find AI tools in YBX
Related Articles
Refresh Articles