Apache Airflow 2.10のご紹介:AIデータオーケストレーションの新時代
Most people like
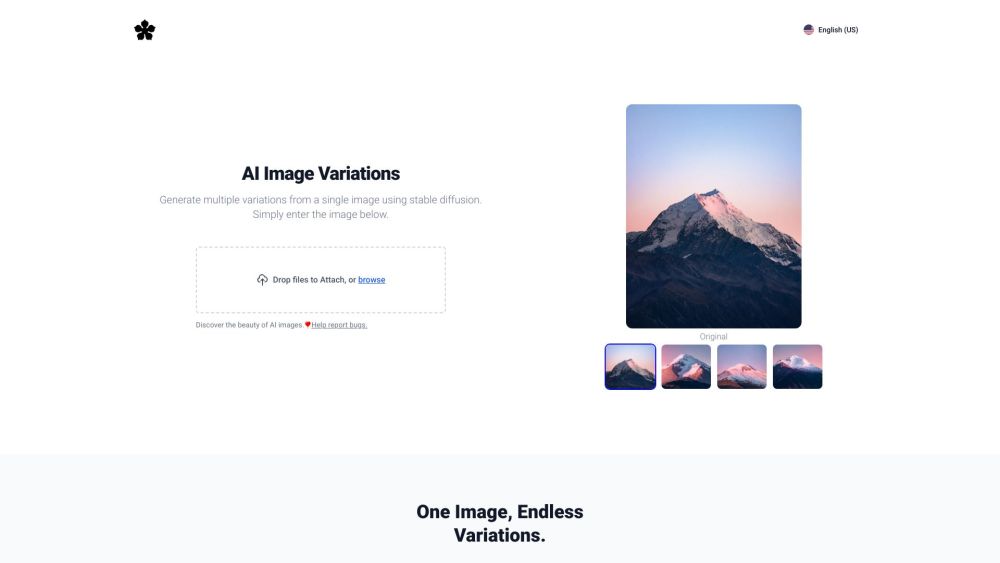
AI画像生成器は、先進的なAI技術を活用して多様な画像バリエーションを生成します。この革新的なツールは、アーティストやデザイナー、クリエイティブな愛好者が独自の視覚的解釈を簡単に探求できるようにします。今日、AI生成画像の無限の可能性を発見しましょう!
API2Dは、さまざまなAIタスク(自然言語処理、機械学習、会話生成、言語翻訳など)をスムーズにサードパーティアプリケーションと接続するために設計された強力なOpenAI APIです。この多用途なツールは、先進的なAI機能を統合しようとする開発者や企業の能力を向上させます。
Guiddeは、企業の動画ドキュメンテーションを効率化するために設計された革新的なAIプラットフォームです。このプラットフォームにより、プロセスは迅速かつ使いやすくなります。Guiddeの強力なツールを活用することで、企業は動画コンテンツの制作と管理を変革し、生産性とコミュニケーションを向上させます。
今日のデジタル環境では、効果的なマーケティングには、観客に響く魅力的なビジュアルが不可欠です。AIを活用したマーケティング動画の制作は、高品質なコンテンツの作成プロセスを効率化し、ブランドが視聴者とより効果的に関わることを可能にします。高度なアルゴリズムと機械学習を駆使することで、企業は注目を集めるだけでなく、コンバージョンを促進するカスタマイズされた動画を作成できるようになりました。AI技術がどのように動画マーケティングをブランド成長とオーディエンスとのつながりを促進するダイナミックなツールに変えるのかを探ってみましょう。
Find AI tools in YBX
Related Articles
Refresh Articles