Apple、NVIDIA、AnthropicがAIモデルのトレーニングに無断でYouTubeトランスクリプトを使用した疑惑
Most people like
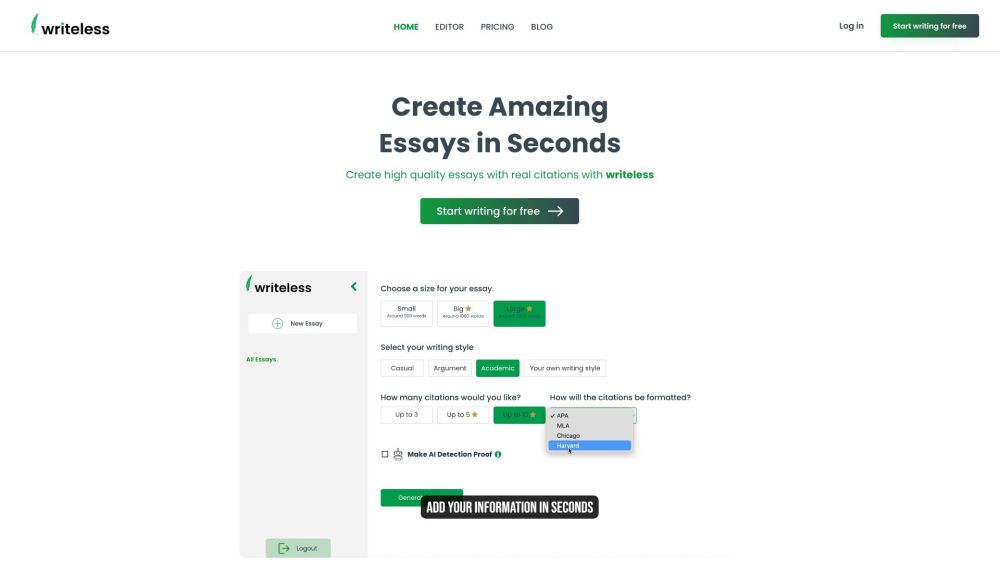
信頼できる引用を用いたAIエッセイ作成の力を引き出しましょう。信頼性の高い情報源に基づいた高品質なエッセイを生成するために設計された高度なAIツールを活用することで、学術的な作品を強化できます。正確性を保ちながら時間を節約し、信頼できる引用により、あなたの執筆を一段と高めましょう。
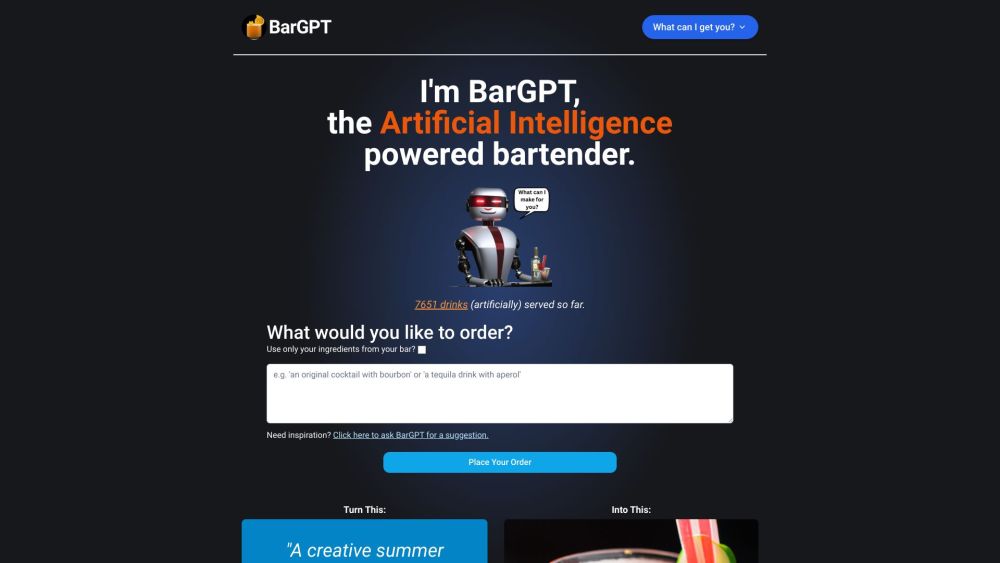
BarGPTは、革新的なAIバーテンダーで、ユニークでクリエイティブなカクテルを作り出し、ミクソロジーの体験を変革します。ありふれた飲み物にさようならし、風味と創造性に満ちたエキサイティングな世界にこんにちは!
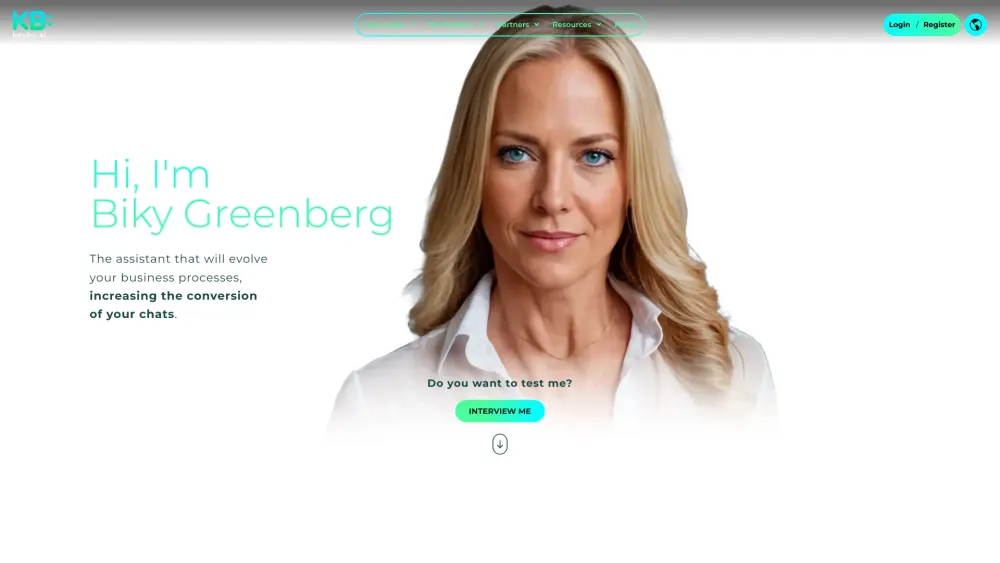
KB: スマートチャットで営業パフォーマンスを向上させましょう
営業チームの潜在能力を引き出し、成果を上げるためにKB: スマートチャットを活用してください。この強力なツールは、顧客とのやり取りを向上させ、コミュニケーションプロセスを効率化するよう設計されています。これにより、売上の増加と顧客満足度の向上を実現します。KB: スマートチャットを活用して、営業戦略を変革し、ビジネスの成長を促進する方法を今すぐ発見しましょう!
Find AI tools in YBX
Related Articles
Refresh Articles