ChatGPTダウンタイム解決策:診断と復旧のための包括的ガイド
Most people like
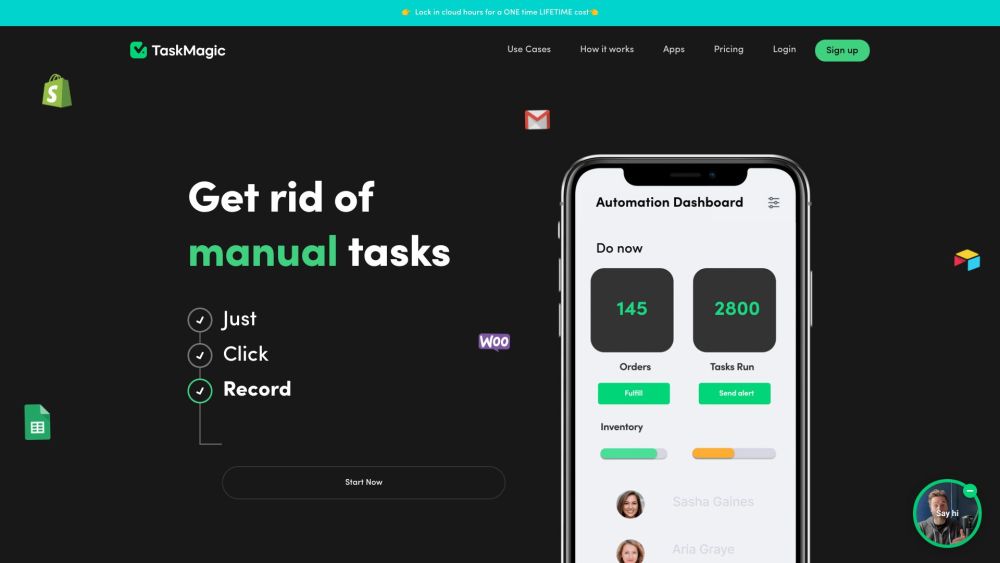
今日の急速に進化する世界では、プロセスを効率的に合理化する能力がこれまで以上に重要です。一度だけ努力を記録することで、自動化されたシステムを構築し、常にあなたのために働かせることができます。これにより、時間を節約し、手作業を減らすことが可能になります。この強力なアプローチを取り入れて、生産性を向上させ、真に大切なことに集中しましょう。
AI駆動のアセット生成でクリエイティブプロジェクトを革新しよう。人工知能の力を利用して、独自で高品質なアセットを簡単に生み出し、デザインプロセスと創造性を向上させます。革新的なAIツールがどのようにあなたのプロジェクトを新たな高みへと引き上げるのかを発見してください。
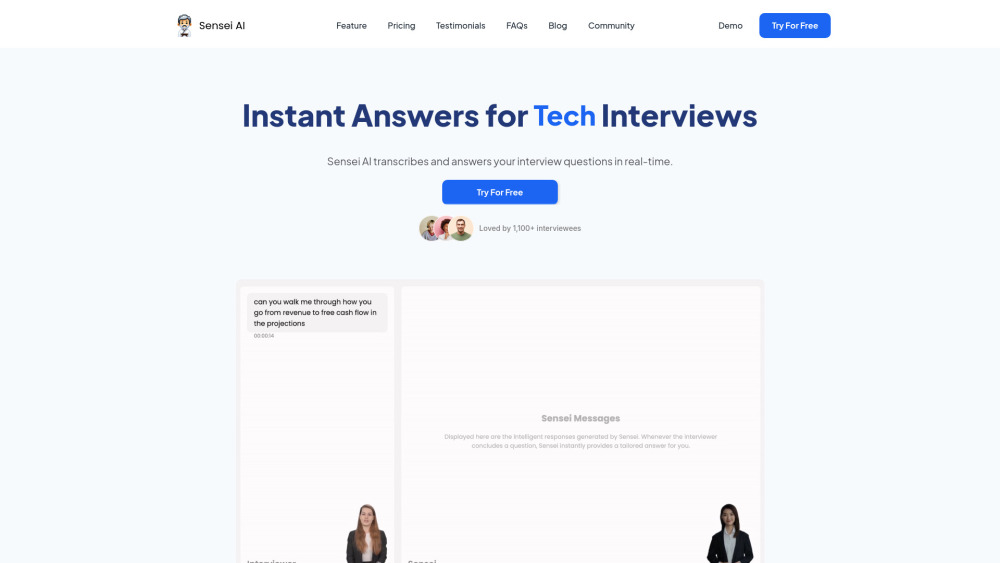
今日の競争が激しい就職市場では、面接で目立つことが夢のポジションを手に入れるために不可欠です。そこで登場するのがAI駆動のインタビューコパイロット—あなたの面接スキルを向上させ、自信を高めるための革新的なツールです。パーソナライズされたコーチング、リアルタイムのフィードバック、そしてカスタマイズされた練習問題を通じて、この革新的なソリューションは求職者が最高のパフォーマンスを発揮できるようサポートします。この技術があなたの面接準備をどのように変革し、キャリアの成功への道を切り開くかをご覧ください。
Find AI tools in YBX
Related Articles
Refresh Articles