MetaのVFusion3D: AI駆動の3Dコンテンツ制作を革新する
Most people like
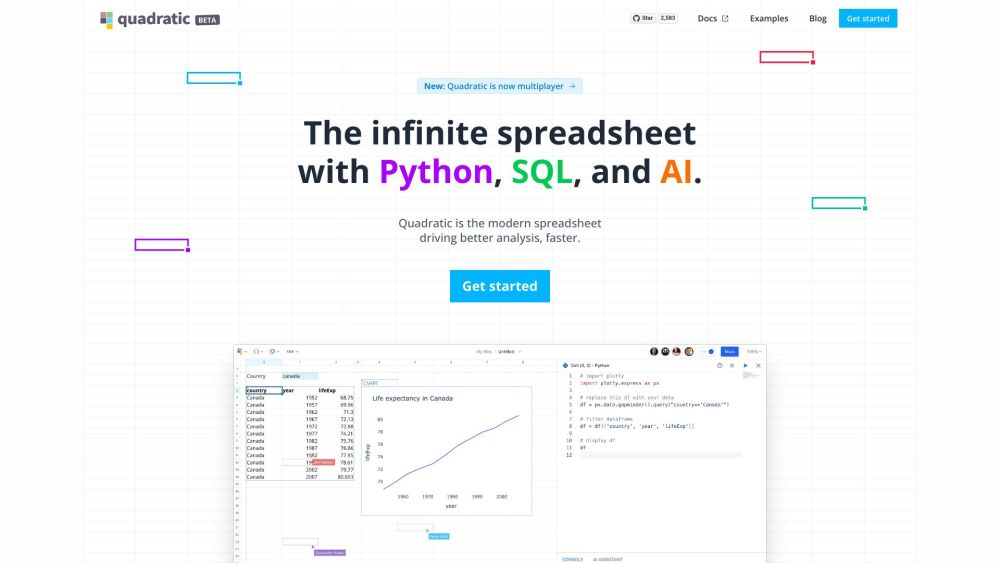
今日の急速に進化するデジタル環境において、開発者はコラボレーションを効率化し、生産性を向上させるための効果的なツールを必要としています。リアルタイムのスプレッドシートは、チームがデータ管理と分析を同時に行える強力なソリューションを提供します。このインタラクティブなアプローチは、スムーズなコミュニケーションを促進するとともに、即時の更新を可能にし、ワークフローを最適化しようとする開発者にとって不可欠なリソースとなります。リアルタイムスプレッドシートの統合が、プロジェクト管理とデータコラボレーションをどのように向上させるかを発見してください。
私たちの無料AI画像生成ツールの力を体験してください。アイデアを驚くほど魅力的なビジュアルに簡単に変換できます。コンテンツクリエイター、マーケター、趣味で活動する方々にも最適で、先進の人工知能を活用してユニークな画像を生成するシンプルで直感的な方法を提供します。今日から目を引くグラフィックを作成し、あなたのビジョンを実現しましょう!

声を変えよう:ゲームとストリーミングのための究極のボイスチェンジャー
ゲームやストリーミング体験を向上させる完璧なボイスチェンジャーを見つけましょう。視聴者を楽しませたい、匿名性を追加したい、あるいは単に楽しみたいという方に最適です。私たちのトップ評価のボイスチェンジャーは、パフォーマンスを向上させ、インタラクションを魅力的に保ちます。さまざまなカスタマイズ可能なエフェクトと使いやすい機能を備え、あなたのゲームスタイルやストリーミングペルソナに合ったユニークなサウンドを作成できます。無限の可能性を探求し、コンテンツを次のレベルへ引き上げましょう!

学生、ビジネス、クリエイターのために設計された究極のオールインワンプラットフォームを発見しましょう。あなたのワークフローを効率化し、多様なニーズに応える一つの統合環境で可能性を引き出してください。
Find AI tools in YBX
Related Articles
Refresh Articles