Microsoft、Florence-2を発表:多様なビジョンタスクに対応した統合モデル
Most people like
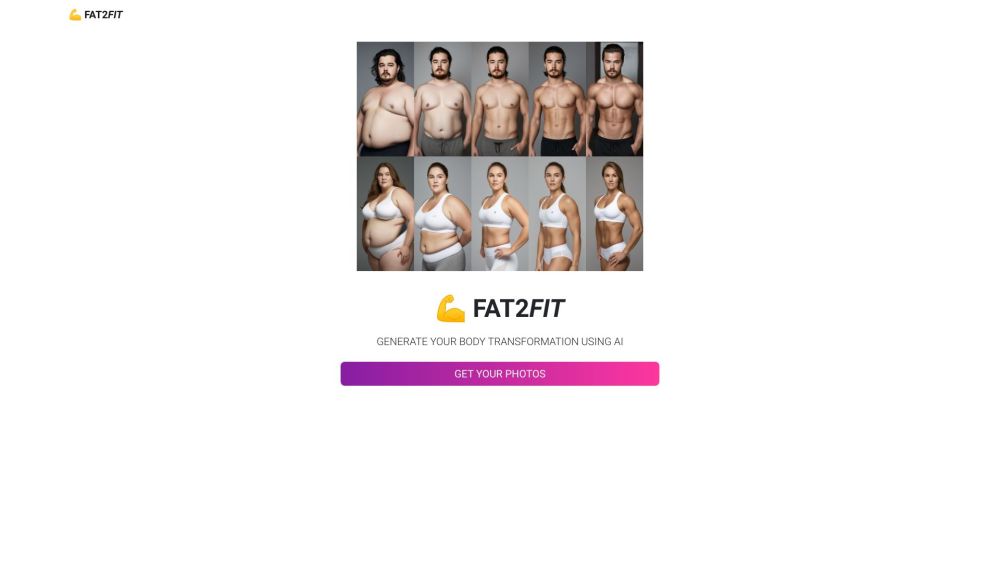
FAT2FITのご紹介:あなたの独自のフィットネス目標に合わせたパーソナライズされたボディトランスフォーメーションを実現する革新的なAI駆動プラットフォームです。最先端の技術と専門家のサポートにより、理想の体型をこれまで以上に効果的に手に入れるお手伝いをします。
Copymaticは、魅力的な広告、引き込まれるウェブコピー、情報豊かなブログコンテンツの作成を迅速に行うための革新的なAI駆動ツールです。高度な機能を備えたCopymaticは、コンテンツ生成をこれまでにないほど迅速かつ効率的にします。
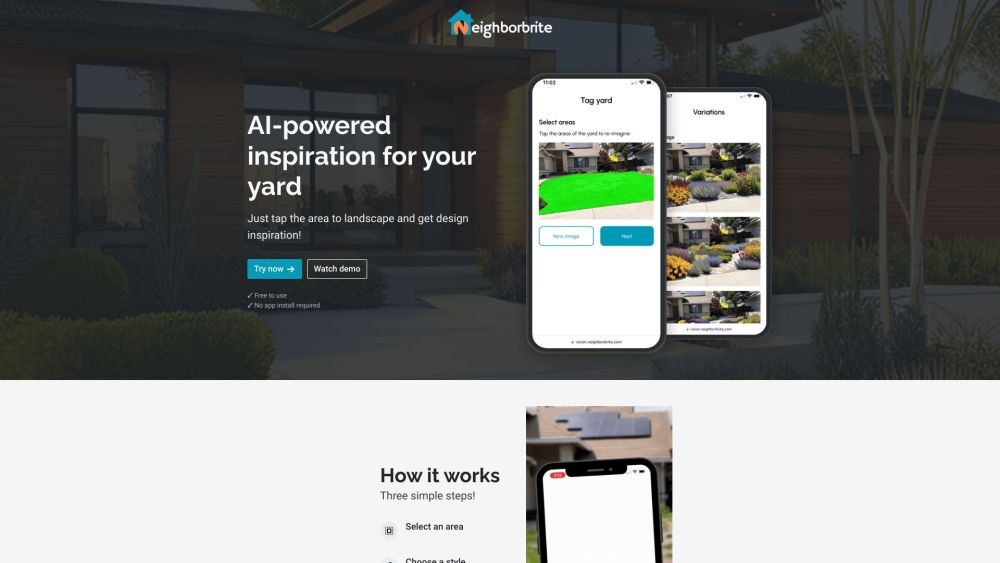
AIを活用したインスピレーションであなたの屋外空間を変革しましょう。革新的なアイデアやカスタマイズされたデザインを見つけて、景観を向上させ、理想的な庭の隠れ家を作り出しましょう。最新の技術を利用して、夢の庭づくりを今日から始めませんか!

歌はしばしば深いメッセージや感情を持ち、リスナーにその背後にある意味を探求することを促します。歌の意味を解釈することは、音楽への理解を深めるだけでなく、アーティストの意図や彼らが伝えたい感情と私たちを結びつけることでもあります。このガイドでは、歌詞を解読し、その中に繰り広げられる物語を理解するためのさまざまな技法を掘り下げます。カジュアルなリスナーでも音楽愛好者でも、歌の意味を解釈することを学ぶことで、リスニング体験が豊かになり、音楽芸術とのより深い結びつきを育むことができます。
Find AI tools in YBX
Related Articles
Refresh Articles