OpenAI、ChatGPT Plusユーザー向けにGPT-4oボイスモードを導入し、自然なリアルタイム会話を向上
Most people like
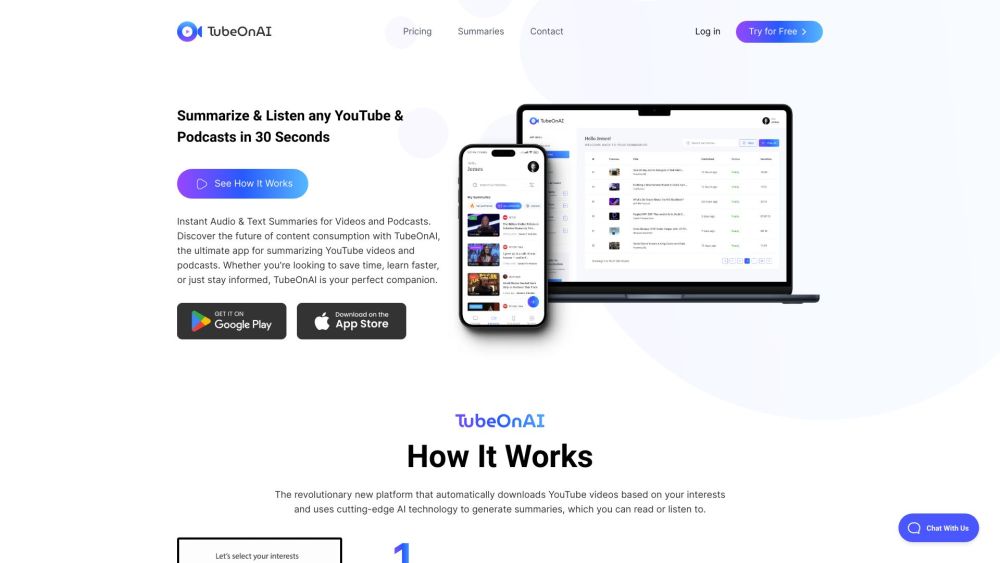
AI駆動の要約で動画視聴を効率化しよう。これらの革新的なツールが視聴体験を向上させ、重要な情報を素早く把握し、時間を節約できる方法を見つけてください。今すぐAI駆動の動画要約で効率を取り入れましょう!
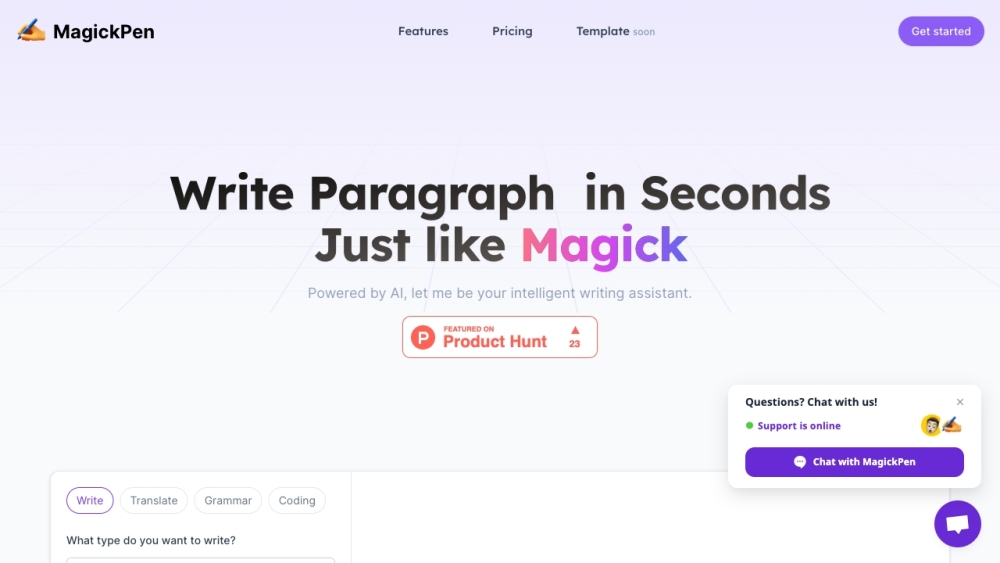
シームレスなテキスト生成のために設計された究極のAI駆動ライティングツールを発見してください。革新的なこのツールを使って、簡単かつ効率的にライティングプロセスを変革し、高品質なコンテンツを手軽に作成しましょう。先進のAI技術があなたの創造性と生産性を高め、ライティング作業をより迅速で楽しいものにします。
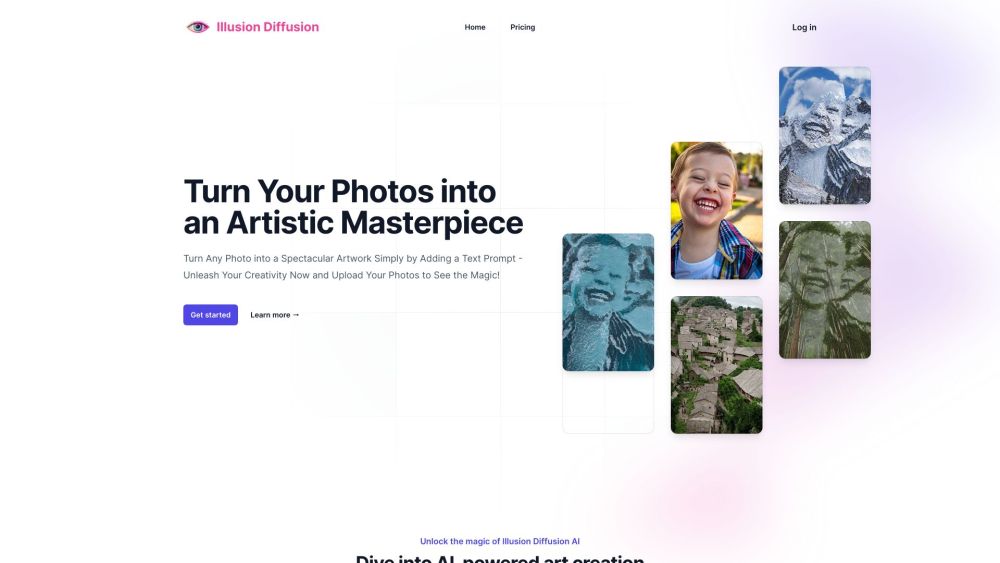
テキストプロンプトを魅力的な視覚のイリュージョンに変えて、魅了し、インスパイアしましょう。言葉を美しいイメージに変換する技術を発見し、想像力を捉えましょう。
Find AI tools in YBX
