OpenAIの研究が明らかにしたAIが生物的脅威開発の未来に与える意外な影響
Most people like

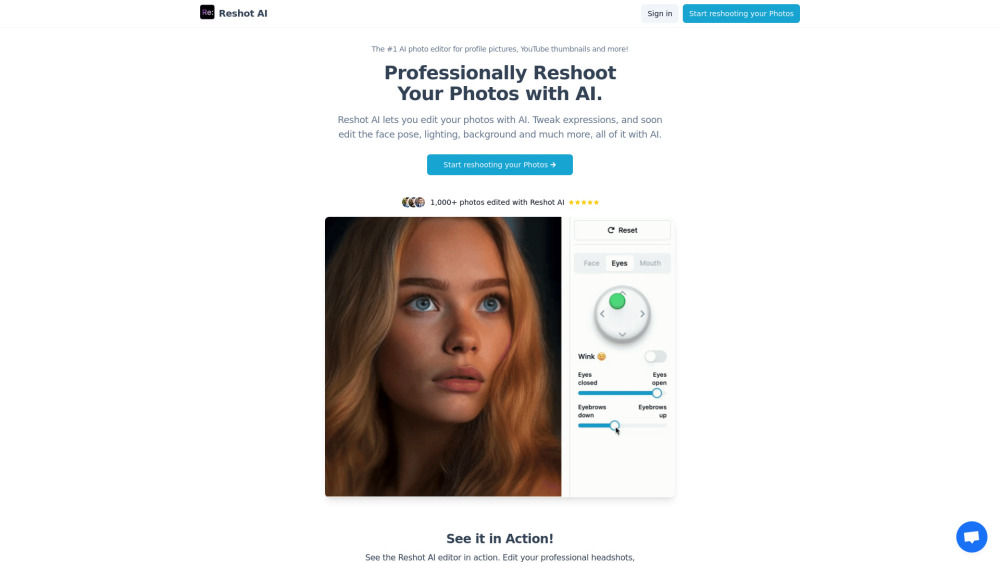
プロフェッショナル品質の向上を実現するAIフォトエディターで、あなたの写真を格上げしましょう。数回のクリックで普通の写真を見事なビジュアルに変えるシームレスな編集を体験してください。
ブログコンテンツを強化し、読者を魅了したいですか?ブログ記事を目を引くインフォグラフィックに変換することは、情報を視覚的に提示する強力な方法です。インフォグラフィックは複雑なデータを簡素化し、共有しやすくすることで、コンテンツのリーチを向上させます。このガイドでは、ライティングを魅力的なインフォグラフィックに変えるための効果的な戦略を探ります。インフォグラフィックの技術を活用して、ブログ投稿の影響力を最大化する方法を見つけましょう!
Find AI tools in YBX
Related Articles
Refresh Articles