アマゾン、アレクサのAIを強化し、より自然な会話を実現
Most people like
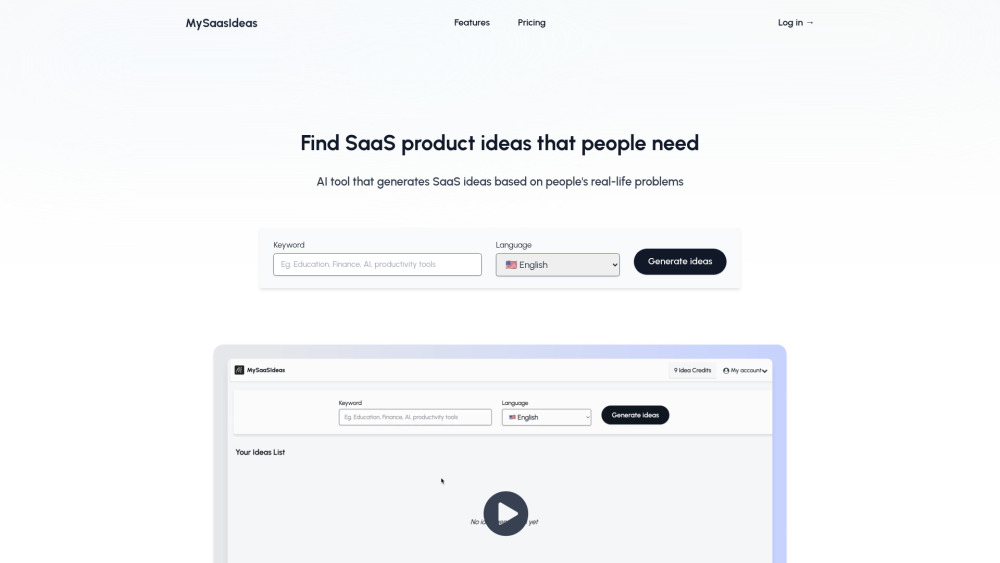
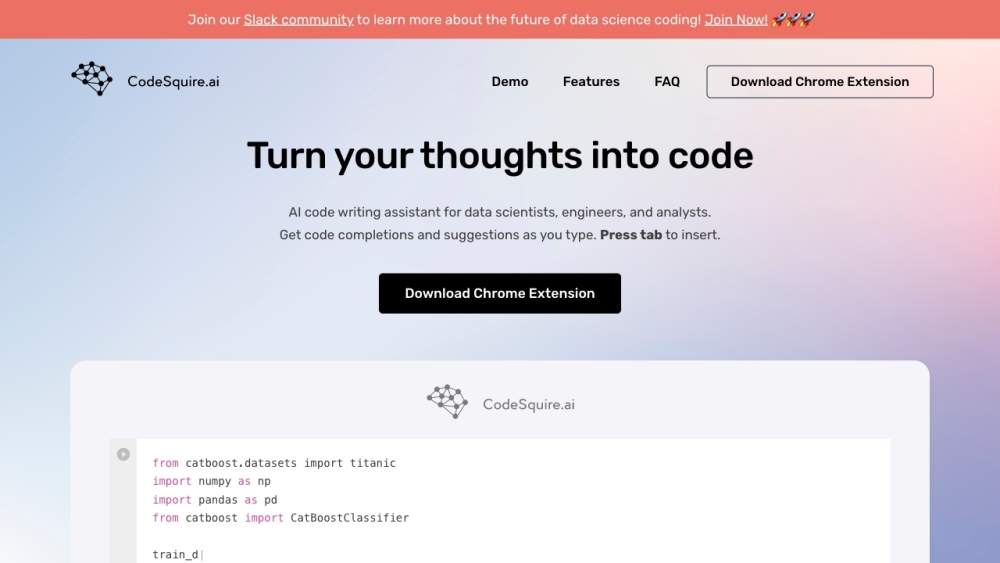
CodeSquireは、データサイエンティストのために特別に設計された革新的なAIアシスタントで、ワークフローを効率化し、生産性を向上させるためにコード機能を容易に生成します。
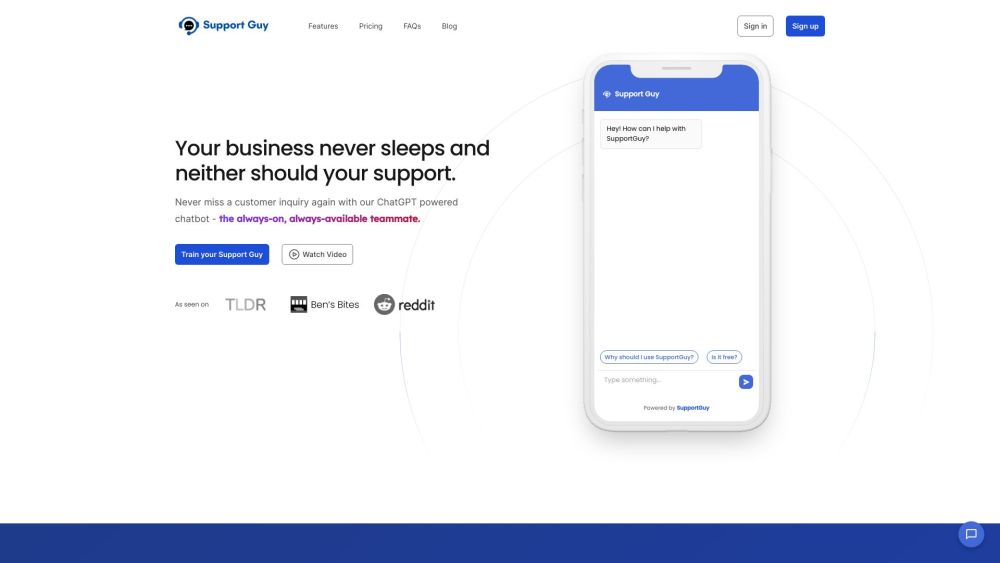
カスタマーサポートの変革、SupportGuyのAI駆動型ChatGPTは、24時間体制で顧客の問い合わせに対応します。いつでも、どこでもシームレスなサポートをこの先進的なソリューションでお楽しみください。
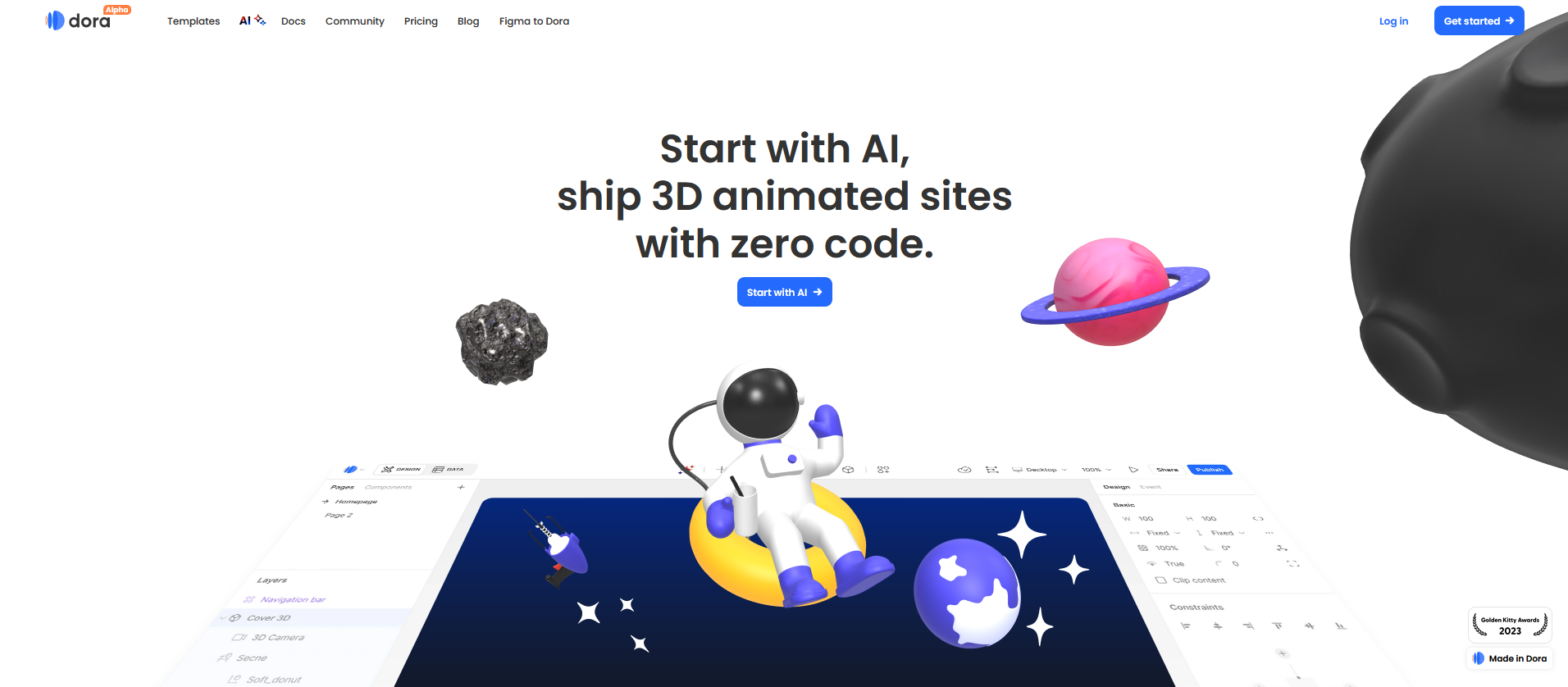
Doraは、デザイナーが魅力的な3Dおよびアニメーションウェブサイトを簡単に作成できるノーコードプラットフォームであり、カスタムかつプロフェッショナルなデザインのためのビジュアルキャンバスを提供します。
Find AI tools in YBX
