アリババ、オープンソースのQwen 1.5-110Bモデルを発表 - MetaのLlama 3-70Bと同等の性能を実現
Most people like

Metaphysic.aiは、ハイパーリアリスティックなAI生成動画コンテンツの最前線に立ち、デジタルストーリーテリングを再定義する驚くべきビジュアルを提供しています。
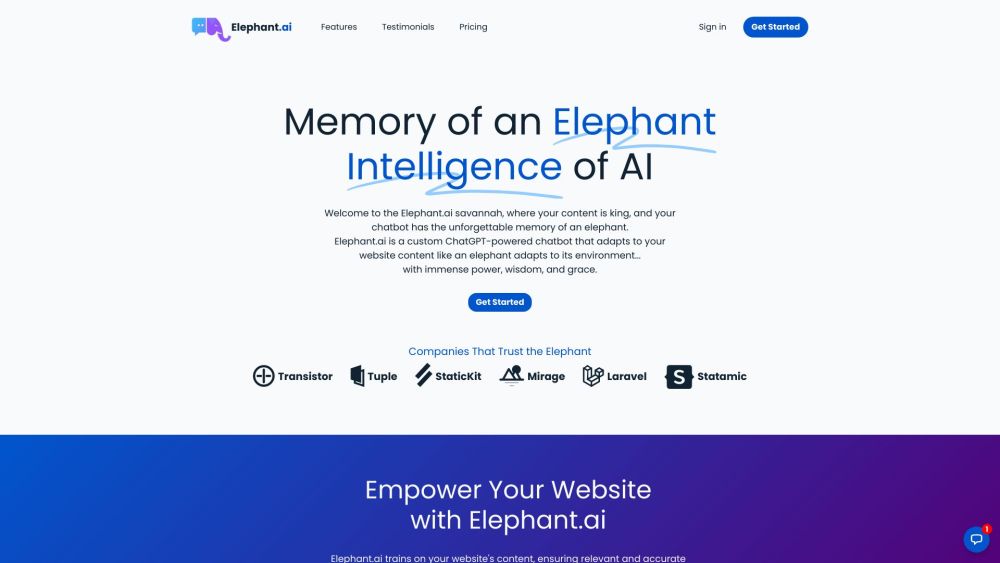
ようこそ、Elephant.aiへ。あなたのウェブサイトの訪問者一人ひとりに対してカスタマイズされた応答を提供するために設計されたパーソナライズチャットボットです。私たちのインテリジェントなAIソリューションで、ユーザーエンゲージメントと満足度を向上させましょう。
Find AI tools in YBX
Related Articles
Refresh Articles