ステーブルオーディオオープン:Stable AIのオープンソース音声生成モデルで音声制作の新たな選択肢を提供
Most people like

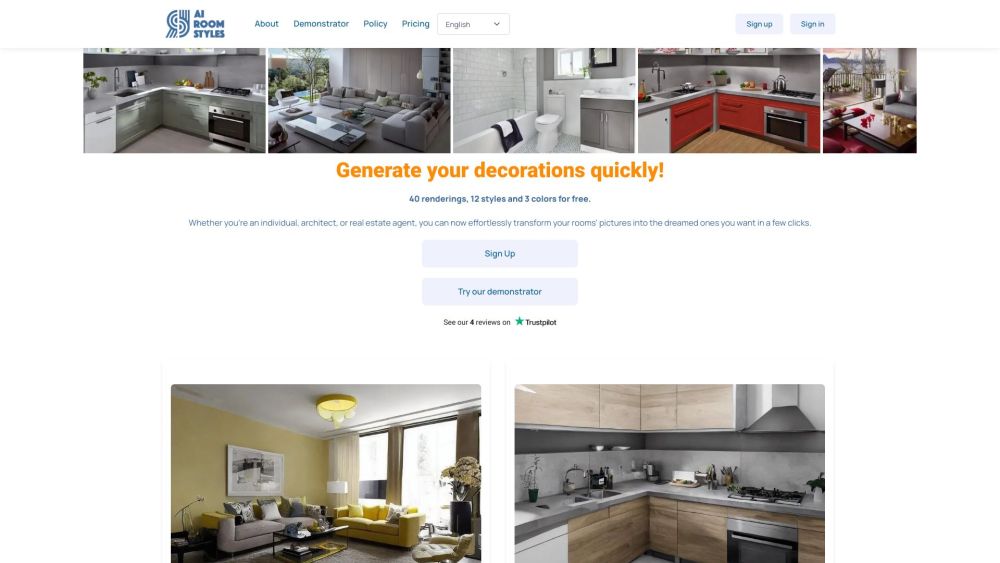
LEAFIO AIリテールプラットフォームを活用して、小売在庫管理を最大化しましょう。小売業者向けに特別に設計された高度なAI駆動ソリューションを通じて、業務を合理化し、効率を向上させ、収益性を高めます。
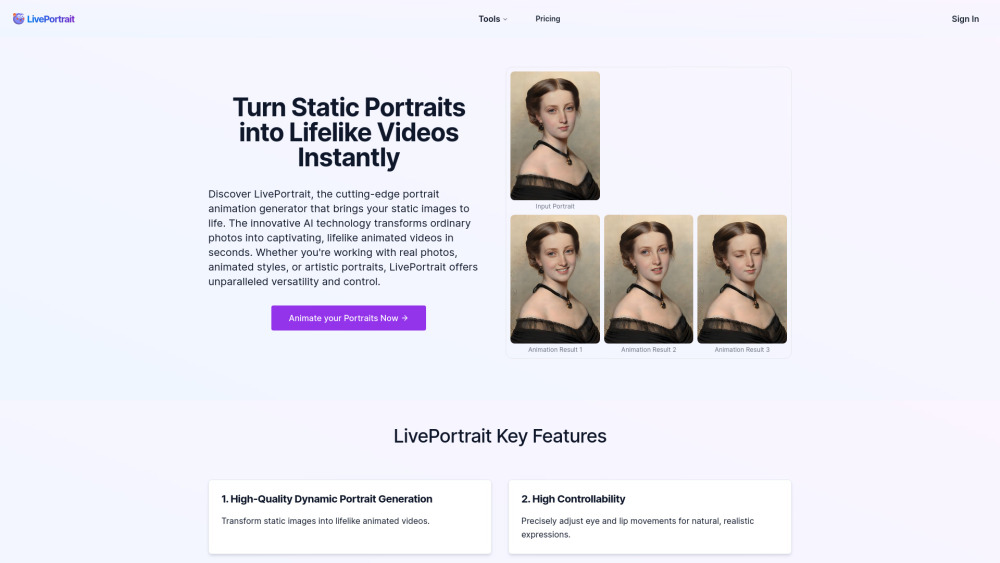
今日の急速に進化するデジタル環境において、AIポートレートアニメーションジェネレーターは画期的なツールとして際立っています。この革新的な技術により、ユーザーは静止画像を生き生きとしたアニメーションに変えることができ、被写体の感情や表情の本質を捉えることができます。個人プロジェクト、ソーシャルメディアコンテンツ、またはプロフェッショナルなプレゼンテーションのために、AIによるポートレートアニメーションの力を活用すれば、視覚的なストーリーテリングやエンゲージメントを向上させることができます。この最先端のツールがどのようにポートレートのアニメーション手法を革新し、観客に共鳴する魅力的なアニメーション体験へと変えることができるのかを発見してみましょう。
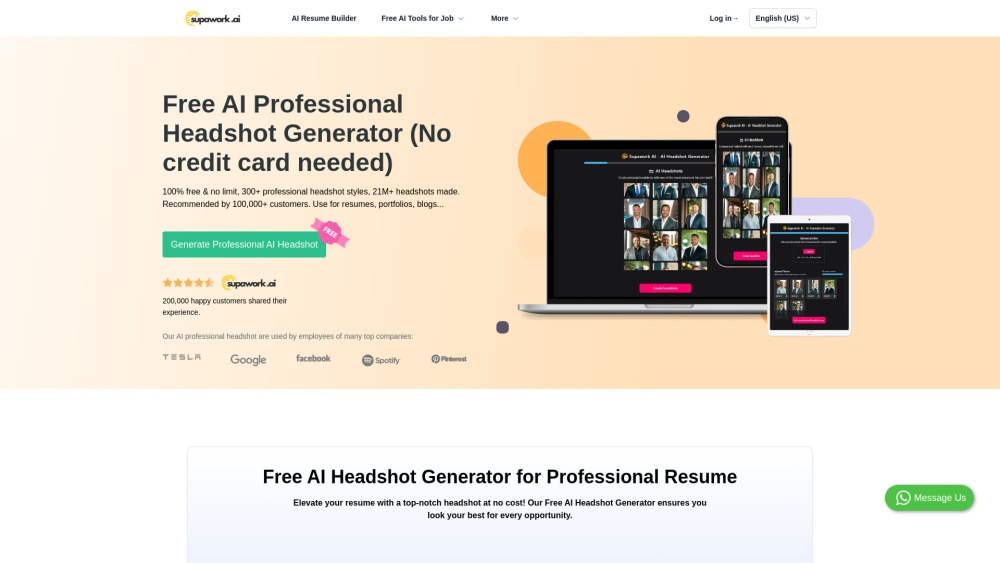
300以上のプロフェッショナルなヘッドショットスタイルと100以上のカスタマイズ可能な背景を探索し、2100万枚以上のポートレートが作成され、5万以上の満足した顧客に信頼されています。AI生成のビジネスヘッドショット、ポートレート、アバター、プロフィール画像を発見し、履歴書、ポートフォリオ、ブログに最適な一枚で、あなたのパーソナルブランドを今日変革しましょう!
Find AI tools in YBX
Related Articles
Refresh Articles