英国AI安全協会、主要な大規模言語モデルの脆弱性を簡易なジャイルブレイキング技術で発見
Most people like
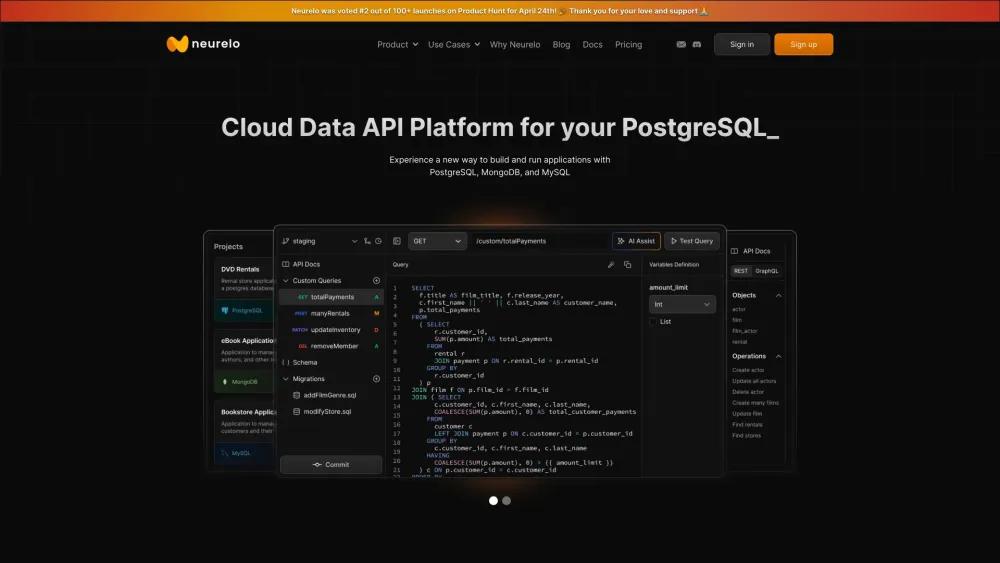
データ主導の現代において、AI搭載のデータベースAPIは、企業がデータを扱い管理する方法を革新しています。人工知能を活用することで、これらのAPIはデータ取得を効率化し、精度を向上させ、よりインテリジェントな意思決定プロセスを可能にします。開発者や企業にとって理想的なAI駆動のデータベースAPIは、パフォーマンスを最適化するだけでなく、組織がデータの可能性を最大限に活用できるようにすることで革新を促進します。AI搭載のデータベースAPIの変革的な影響を探求し、それがデータ管理戦略をどのように向上させるかを考えてみましょう。


私たちのAI宿題サポーターを紹介します。これは、すべての学問的ニーズに対して正確な解決策とガイダンスを提供するように設計されています。複雑な数学の問題に取り組む際やエッセイを書いたり、研究を行ったりする際に、このインテリジェントなツールが正確で信頼性のある答えを提供し、学習体験を向上させます。今すぐ学問の可能性を解き放ちましょう!
Find AI tools in YBX
