구글, AI 역량 향상을 위한 첫 번째 오픈 멀티모달 비전-언어 모델 'PaliGemma' 출시
Most people like
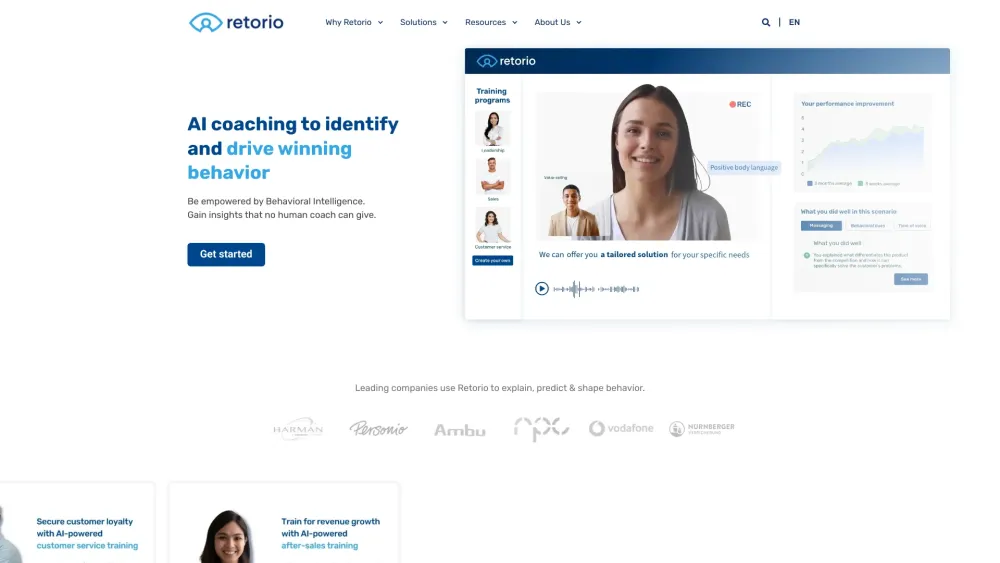
성과 중심 문화의 잠재력을 여는 것은 행동 지능에 기반한 효과적인 학습 및 개발(L&D) 전략에 달려 있습니다. 행동 과학의 통찰력을 통합함으로써 조직은 직원 참여를 강화하고, 훈련 프로그램을 효율화하며, 더 역동적인 작업 환경을 조성할 수 있습니다. 이러한 접근 방식은 지속적인 학습을 촉진할 뿐만 아니라 직원 성장과 비즈니스 목표를 일치시켜 조직의 성공을 이끕니다. 행동 지능에 뒷받침된 혁신적인 L&D 관행을 통해 thriving 성과 문화를 어떻게 배양할 수 있는지 알아보십시오.

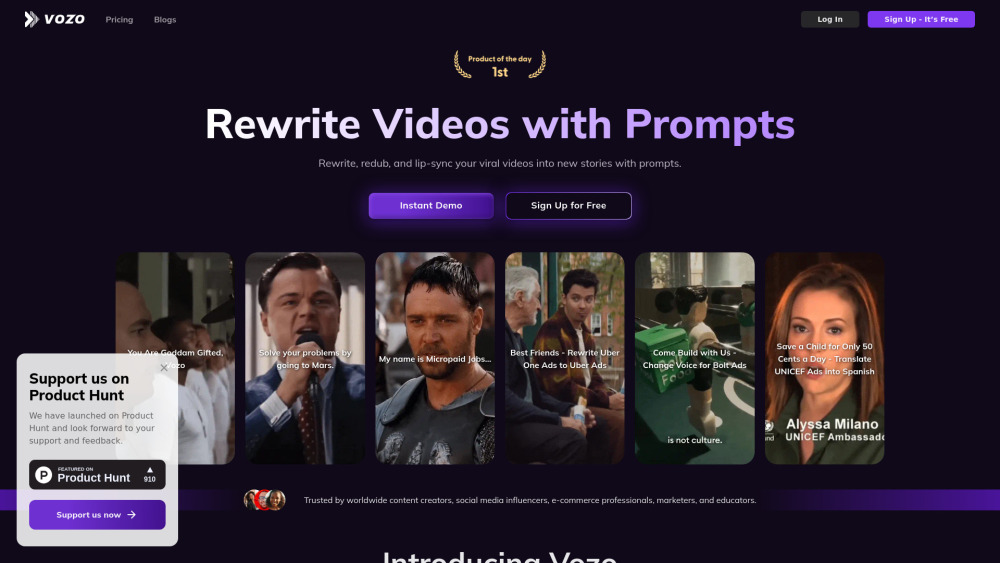
AI 비디오 생성기로 비디오 콘텐츠의 잠재력을 열어보세요. 이 도구는 비디오 변환 과정을 간소화하고 향상시킵니다. 매력적인 마케팅 자료, 역동적인 소셜 미디어 클립 또는 매력적인 교육 비디오를 제작하고자 하신다면, 이 혁신적인 도구가 고품질 결과물을 손쉽게 만들어 드립니다. 비디오 제작의 미래를 받아들이고, AI와 함께 여러분의 창의적인 아이디어를 현실로 만들어 보세요.
Find AI tools in YBX
Related Articles
Refresh Articles