Zyphra, Zyda 출시: Pile, C4, arXiv를 초월할 것으로 보이는 1.3T 언어 모델링 데이터셋
Most people like
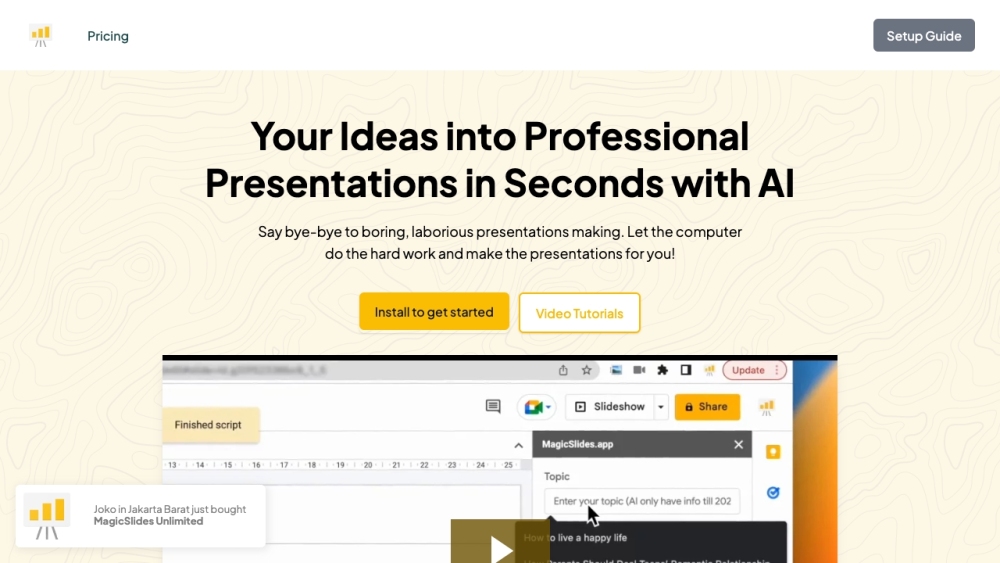
매직 슬라이드는 인공지능의 힘을 활용하여 모든 텍스트 입력에서 매혹적인 프레젠테이션 슬라이드를 생성합니다. 귀하의 아이디어를 손쉽게 매력적인 시각적 프레젠테이션으로 변환하세요!
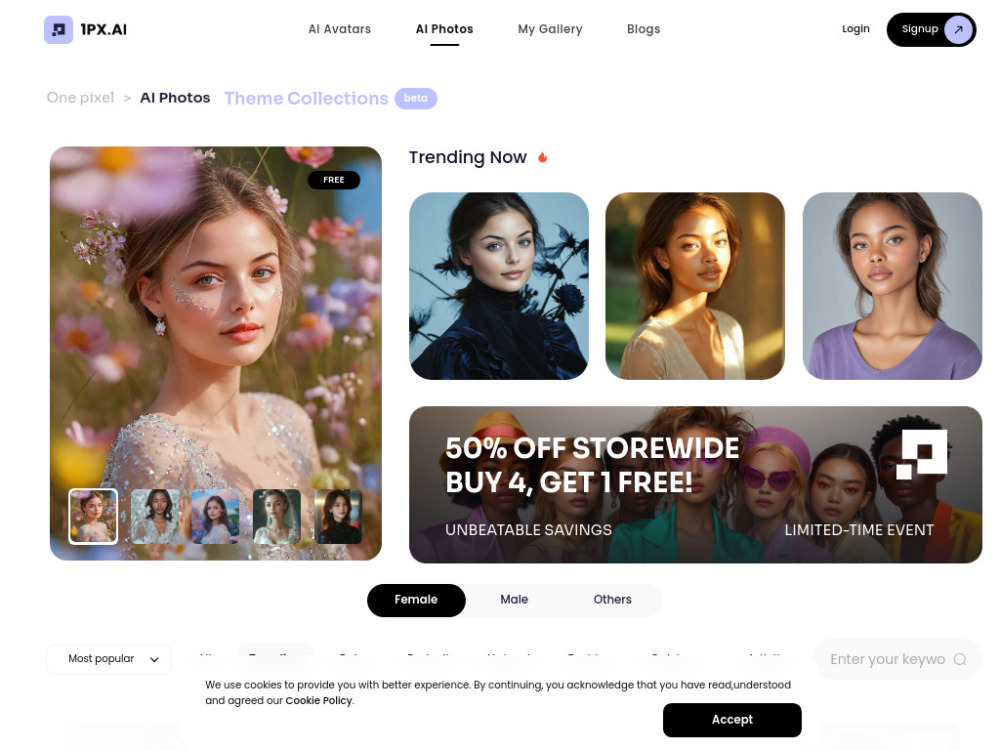
오늘날 디지털 세계에서는 독특하고 개인화된 아바타나 사진 변환을 만드는 것이 그 어느 때보다 쉬워졌습니다. 최첨단 AI 기술을 통해, 우리의 AI 아바타 및 사진 생성기는 사용자가 눈길을 사로잡는 디지털 표현을 손쉽게 디자인할 수 있게 해줍니다. 온라인 존재감을 강화하거나 창의력을 표현하든, 이 혁신적인 도구는 사용자의 요구에 맞춘 고품질 이미지를 쉽게 생성할 수 있도록 돕습니다. 아이디어를 시각으로 변환하고 오늘 AI 아바타 생성의 힘을 경험해 보세요!

친근한 AI 수학 튜터를 만나보세요. 수학 학습을 재미있고 접근 가능하게 만들어드립니다! 직관적인 플랫폼을 통해 기본 산수부터 고급 미적분까지 개인 맞춤형 지원을 받아보세요. 수많은 학습자들이 우리의 인터랙티브 수업과 즉각적인 피드백으로 자신감과 실력을 키우고 있습니다. 함께 수학 잠재력을 열어봅시다!
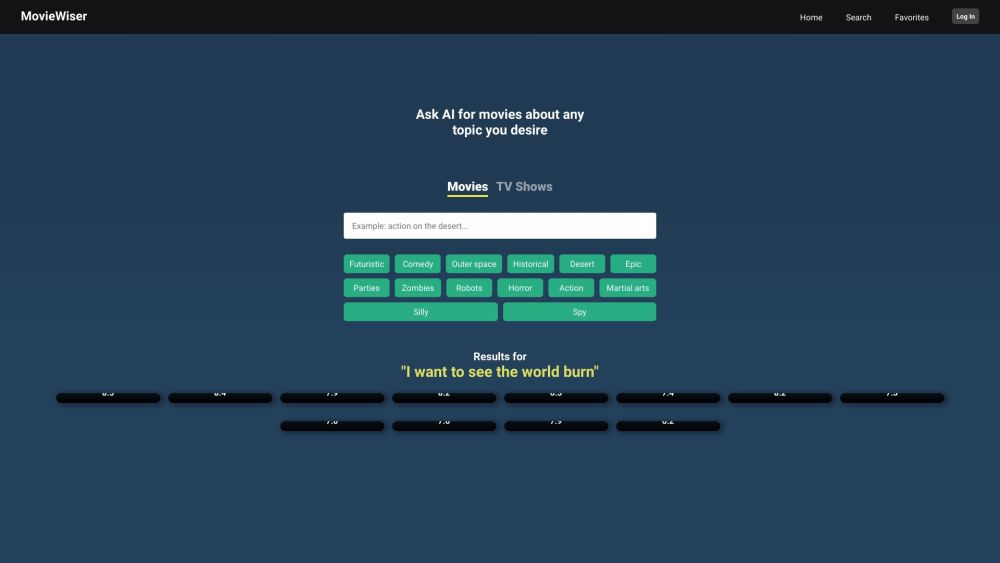
무비와이저는 당신의 독특한 취향에 맞춰 영화와 TV 시리즈를 추천하는 지능형 AI 기반 플랫폼입니다. 고급 알고리즘을 이용해 무비와이저는 다음에 좋아할 영화나 프로그램을 찾는 과정을 간소화하여 개인화된 엔터테인먼트 추천을 그 어느 때보다 쉽게 만들어줍니다. 당신의 취향에 맞는 큐레이션된 콘텐츠의 세계를 발견하세요!
Find AI tools in YBX
Related Articles
Refresh Articles