구글 딥마인드, '슈퍼휴먼' AI 시스템 출시: 사실 확인 혁신, 비용 절감 및 정확성 향상
Most people like
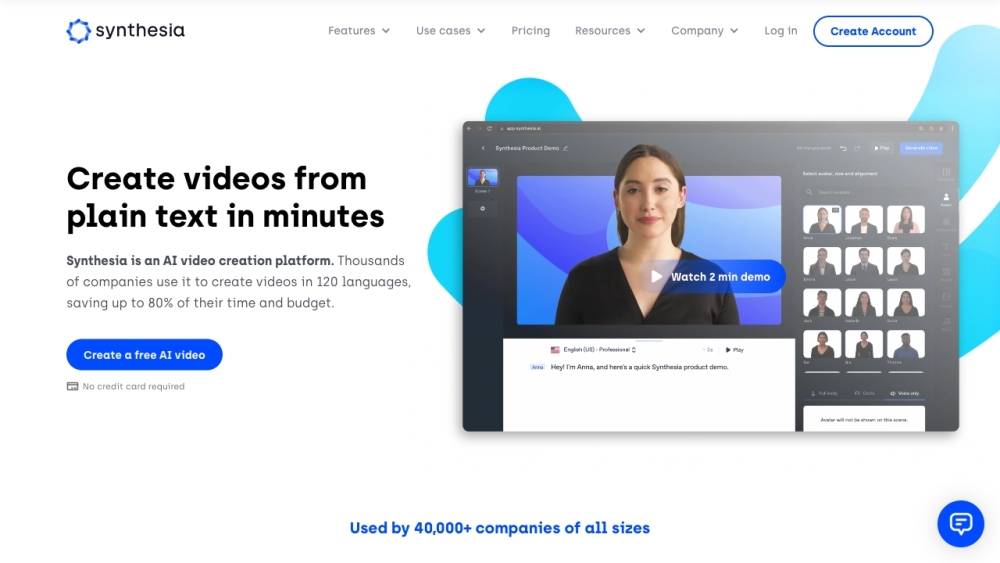
AI 아바타와 다국어 음성 해설을 활용하여 전문적인 비디오를 쉽게 제작하세요. 배우나 비싼 장비는 필요 없습니다. 오늘 바로 원활한 비디오 제작 경험을 시작하세요!
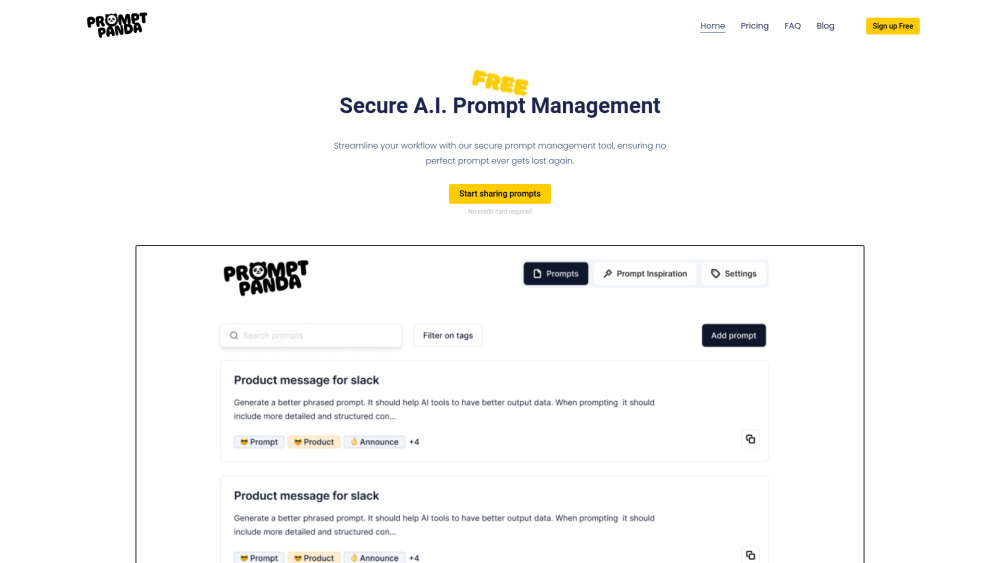
오늘날의 빠르게 변화하는 디지털 환경에서 효과적인 AI 프롬프트 관리는 워크플로우 최적화에 필수적입니다. 인공지능의 힘을 활용하면 프로세스를 간소화하고 생산성을 향상시키며 전반적인 효율성을 극대화할 수 있습니다. 이 가이드에서는 AI 프롬프트 관리를 마스터하기 위한 주요 전략과 도구를 탐구하여 귀하의 운영이 원활하고 효과적으로 진행될 수 있도록 도와드립니다.

ARM 및 헬스케어 분야를 위한 AI 기반 워크플로우 플랫폼 소개
우리의 첨단 AI 기반 워크플로우 플랫폼이 채권 관리(ARM) 및 헬스케어 산업을 어떻게 혁신하는지 알아보세요. 프로세스를 간소화하고 운영 효율성을 향상시킴으로써, 우리 플랫폼은 조직이 워크플로우를 최적화하고 환자 결과를 개선하며 수익 주기를 가속화할 수 있도록 지원합니다. 귀하의 필요에 맞춘 첨단 기술로 산업 혁신의 미래를 탐험해 보세요.
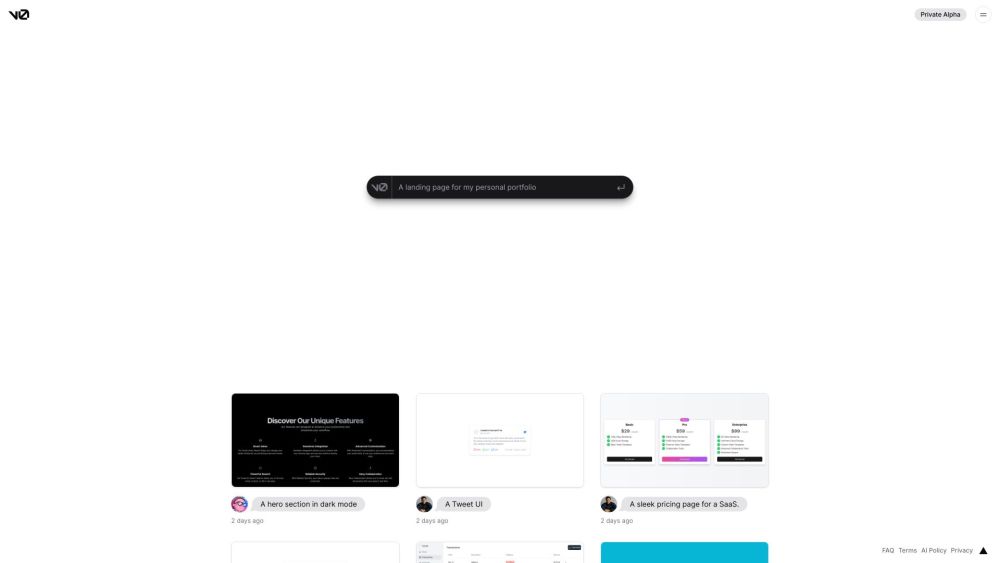
AI 기반 생성 UI 시스템을 소개합니다. 사용자 경험을 혁신하도록 설계된 이 혁신적인 기술은 인공지능의 힘을 활용하여 개인의 요구와 선호에 맞게 동적이고 반응적인 사용자 인터페이스를 생성합니다. 우리의 생성 접근 방식이 디자인 효율성을 향상시키고 상호작용 품질을 높이는 방법을 알아보세요.
Find AI tools in YBX
Related Articles
Refresh Articles