구글, 현실감 있는 AI 비디오 제작을 위한 공간-시간 확산 모델 '루미에르' 공개
Most people like
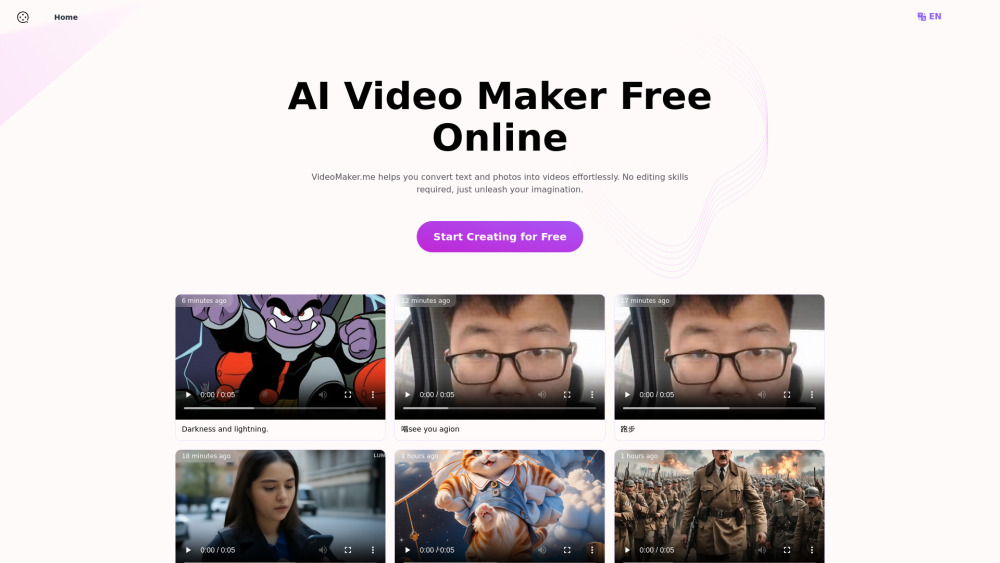
우리의 AI 비디오 제작기의 강력함을 경험해 보세요. 고급 텍스트-투-비디오 및 이미지-투-비디오 기능을 갖춘 이 도구로, 글과 이미지를 매력적인 비주얼 스토리로 변환하여 손쉽게 멋진 영상을 만들 수 있습니다. 콘텐츠 제작자, 마케팅 전문가, 사업주 누구나 이 직관적인 도구를 이용해 몇 분 안에 프로 수준의 비디오를 제작할 수 있습니다. 오늘 우리의 혁신적인 기능으로 창의력을 발휘하고 비디오 콘텐츠를 한 단계 끌어올려 보세요!
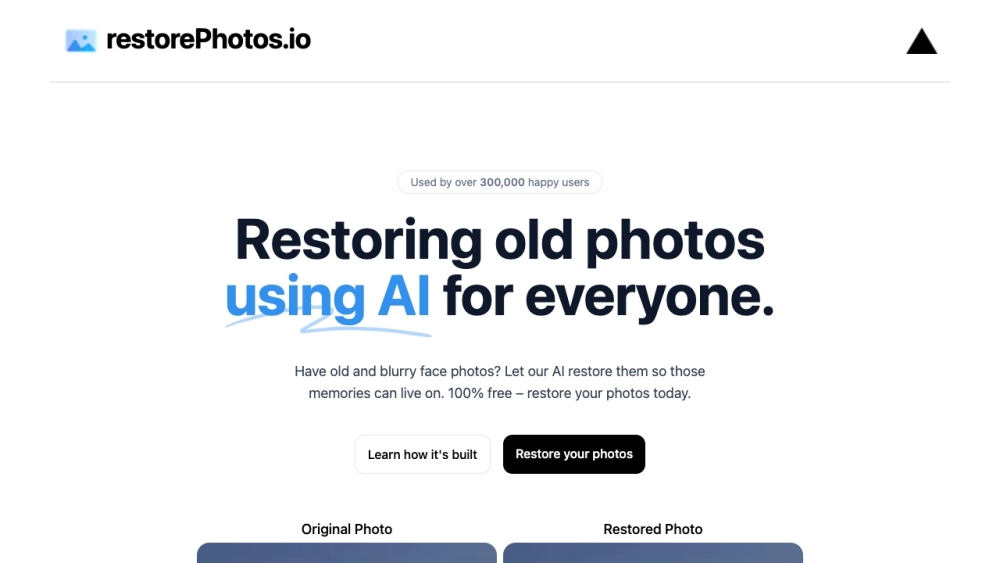
고급 AI 기술을 활용하여 오래되고 흐릿한 사진을 개선하는 혁신적인 플랫폼으로 소중한 추억을 되살리세요. 희미한 얼굴 이미지를 선명하고 생동감 있는 기념품으로 변모시켜 소중한 순간이 오랫동안 간직될 수 있도록 합니다.

유튜브 요약 소개, YouTube 비디오와 팟캐스트의 간결한 요약을 손쉽게 만들어주는 혁신적인 AI 도구입니다. 고급 알고리즘을 통해 유튜브 요약은 길고 복잡한 콘텐츠를 쉽게 소화할 수 있는 하이라이트로 변환하여 필요한 정보를 빠르게 접근할 수 있도록 돕습니다.
Find AI tools in YBX
Related Articles
Refresh Articles