메타의 이미지 생성 모델 확장: 비디오 및 향상된 이미지 편집 기능 추가
Most people like

목소리를 변환하세요: 게임 및 스트리밍을 위한 궁극의 목소리 변환기
게임 및 스트리밍 경험을 한층 향상시킬 완벽한 목소리 변환기를 만나보세요. 관객을 즐겁게 하거나 익명성을 추가하거나 단순히 재미를 느끼고 싶다면, 저희의 최고 평점 목소리 변환기가 여러분의 퍼포먼스를 향상시키고 상호작용을 흥미롭게 유지합니다. 다양한 사용자 맞춤 효과와 편리한 기능을 통해 게임 스타일이나 스트리밍 페르소나에 맞는 독특한 사운드를 생성할 수 있습니다. 끝없는 가능성을 탐색하고 콘텐츠를 한 단계 끌어올리세요!
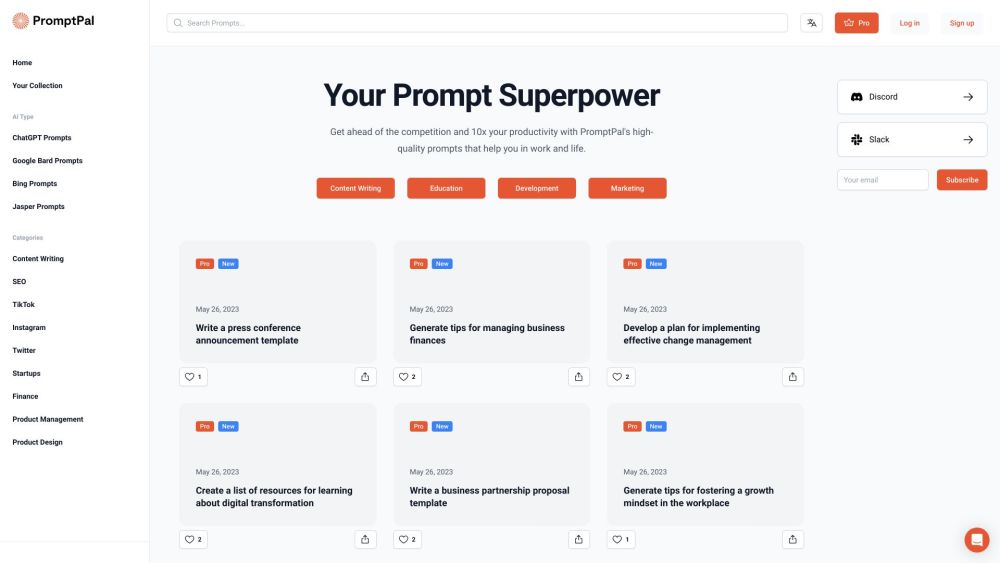
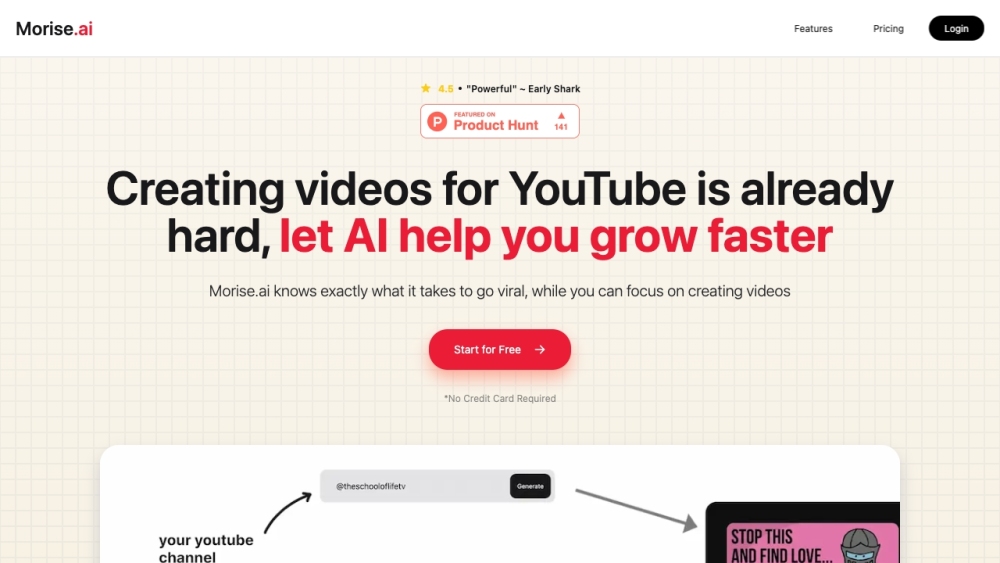
YouTube 창작자를 위해 특별히 설계된 AI 기반 툴박스로 여러분의 창의력을 발휘하세요. 이 혁신적인 도구 세트는 영상 제작을 향상시키고, 콘텐츠 전략을 최적화하며, 관객 참여를 높여 채널 성장의 길을 더욱 쉽게 만들어 줍니다. 영상 제작의 미래를 받아들이고 YouTube의 꿈을 실현해 보세요!
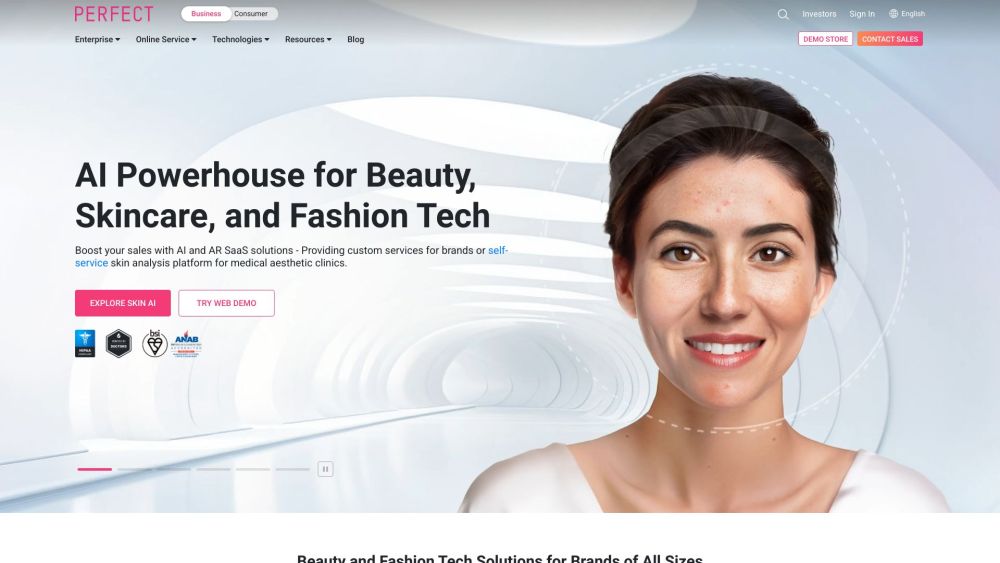
AI와 AR 솔루션이 뷰티, 패션, 스킨케어 산업에서 변화시키는 힘을 발견하세요. 기술이 계속 발전함에 따라, 이러한 혁신적인 도구들은 브랜드가 소비자와 소통하고, 경험을 향상시키며, 맞춤형 제공을 하는 방식을 재구성하고 있습니다. 인공지능과 증강 현실이 제품 발견, 가상 착용, 맞춤 추천을 혁신하며, 보다 몰입감 있고 사용자 친화적인 쇼핑 경험을 만들어가는 과정을 탐험해 보세요. 경쟁 환경에서 앞서 나가고, 브랜드의 성장과 성공을 위한 AI와 AR의 잠재력을 활용하세요.
Find AI tools in YBX
Related Articles
Refresh Articles