애플, NVIDIA, 그리고 Anthropic이 AI 모델 훈련을 위해 유튜브 전사를 무단 사용한 혐의가 제기되었습니다.
Most people like
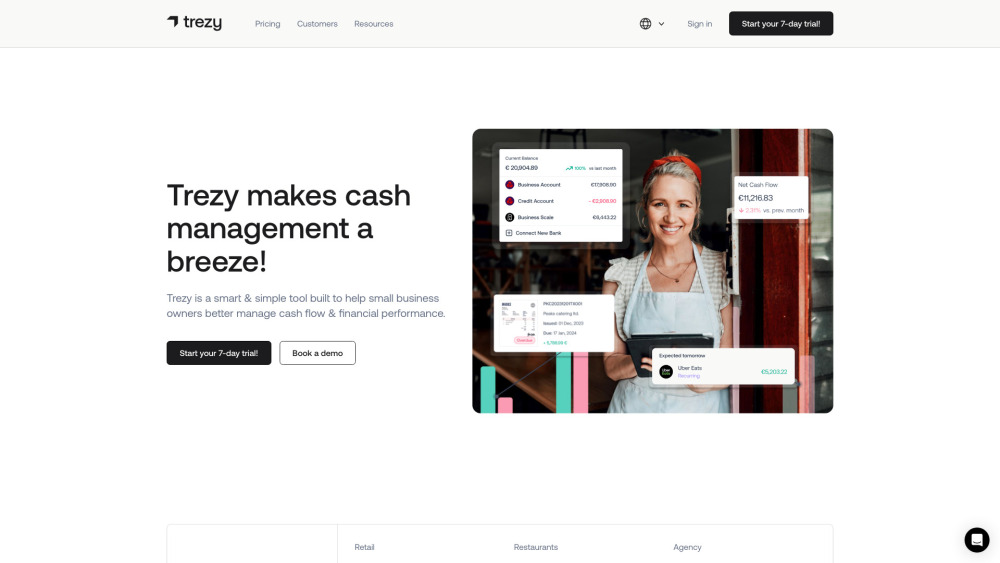
중소기업을 위한 효과적인 현금 흐름 관리 도구
오늘날의 빠르게 변화하는 경제 환경에서 중소기업은 독특한 재정적 도전에 직면해 있습니다. 안정적인 현금 흐름을 확보하는 것은 운영 유지, 의무 이행, 성장 촉진에 매우 중요합니다. 이 기사에서는 중소기업에 맞춘 최고의 현금 흐름 관리 도구를 소개하며, 재무 프로세스를 간소화하고 의사 결정을 개선할 수 있도록 설계되었습니다. 비용 추적, 수익 예측 또는 전반적인 재무 건강 개선을 원하시든, 이 도구들은 현금 흐름을 관리하고 비즈니스를 성공으로 이끄는 데 도움을 줄 수 있습니다.
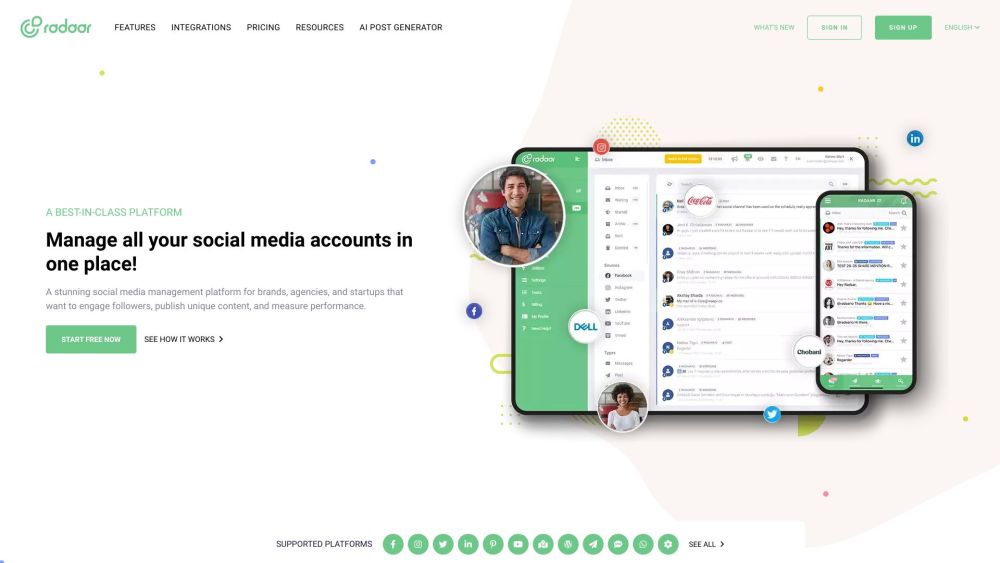
RADAAR를 만나보세요. 브랜드, 에이전시, 스타트업을 위해 설계된 올인원 소셜 미디어 관리 플랫폼입니다. RADAAR의 강력한 기능으로 온라인 존재감을 간소화하고, 참여도를 높이며, 마케팅 효과를 극대화하세요. 다양한 요구를 충족시키기 위해 맞춤화된 솔루션을 제공합니다.
Find AI tools in YBX
