Presidente da OpenAI Apresenta a Primeira Imagem Criada pelo GPT-4o
Most people like
Crie narrações cativantes sem esforço com a avançada tecnologia de Texto para Fala da SpeechGen.io, proporcionando realismo e qualidade impressionantes.
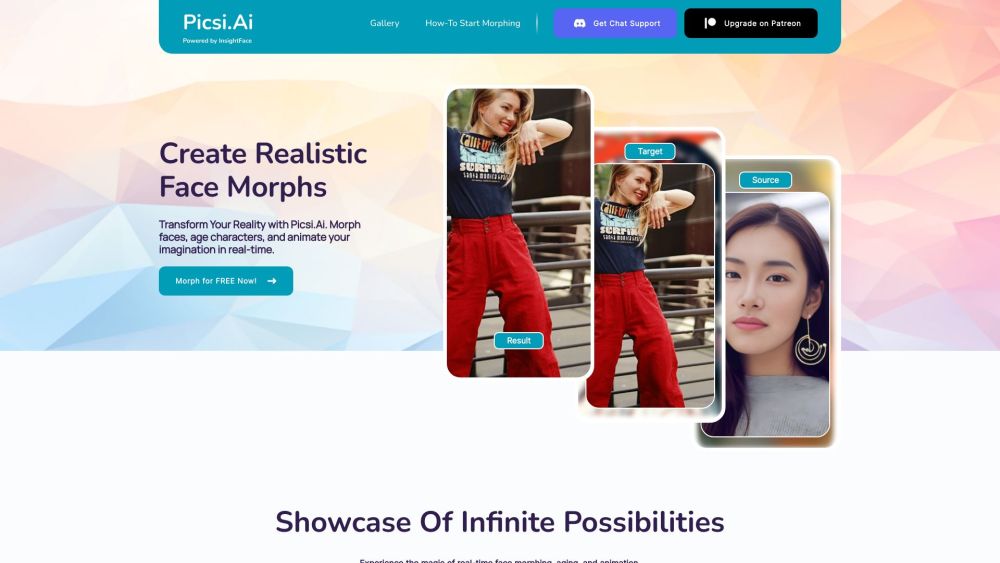
Experimente uma precisão incomparável na tecnologia de transformação facial impulsionada por IA.

Descubra um aplicativo online inovador que cria vídeos deepfake trocando rostos de forma fluida, priorizando a privacidade do usuário. Experimente uma tecnologia de ponta que une criatividade e segurança, permitindo explorar o fascinante mundo da criação de vídeos deepfake.
Find AI tools in YBX
