Zyphra Lança Zyda: Um Conjunto de Dados de Modelagem de Linguagem de 1,3T que Promete Superar Pile, C4 e arXiv
Most people like
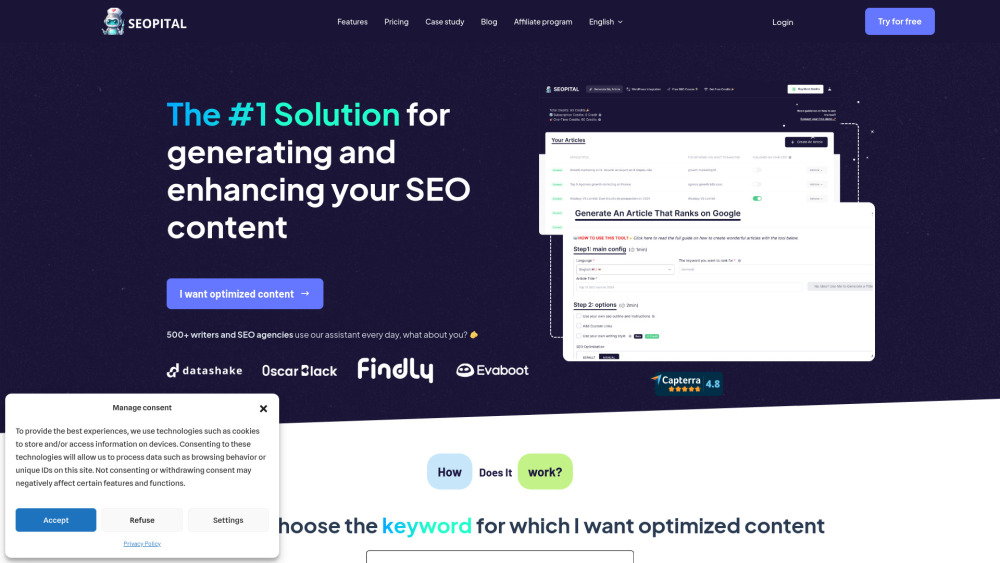
No cenário digital atual, criar conteúdo de alta qualidade é essencial para melhorar sua visibilidade online. Com o aumento dos algoritmos de mecanismos de busca que priorizam informações relevantes e valiosas, um assistente de escrita com IA para SEO pode ser sua arma secreta. Essa ferramenta não apenas agiliza o processo de escrita, mas também otimiza o conteúdo para garantir que ele tenha um melhor posicionamento nos resultados de busca. Seja você um escritor experiente ou novato na criação de conteúdo, utilizar a tecnologia de IA pode levar a melhorias impressionantes no engajamento e alcance do público. Descubra como usar um assistente de escrita com IA para SEO pode elevar sua estratégia de conteúdo e aumentar o tráfego orgânico para seu site.

Apresentando a Plataforma de Chat com Personagens NSFW Picantes: Mergulhe em um ambiente envolvente e divertido, onde personagens de temática adulta ganham vida através de tecnologia de IA avançada. Conecte-se com uma variedade de personalidades enquanto explora conversas estimulantes e cenários únicos adaptados às suas preferências. Experimente uma mistura emocionante de fantasia e interação, tudo isso em um espaço seguro e amigável para o usuário. Junte-se hoje e descubra as possibilidades emocionantes!

O AutoDraw melhora a experiência de esboço ao oferecer sugestões de ícones e desenhos relevantes, adaptadas às entradas dos usuários. Esta ferramenta inovadora simplifica o processo criativo, permitindo que qualquer pessoa transforme rapidamente suas ideias em visuais bem elaborados.
Descubra um recurso abrangente para insights em aprendizado de máquina, com análises de especialistas e atualizações de grandes empresas do setor.
Find AI tools in YBX
Related Articles
Refresh Articles