aiOla Lança Modelo de Reconhecimento de Fala 'Multi-Head' Ultra-Rápido, Superando o OpenAI Whisper
Most people like
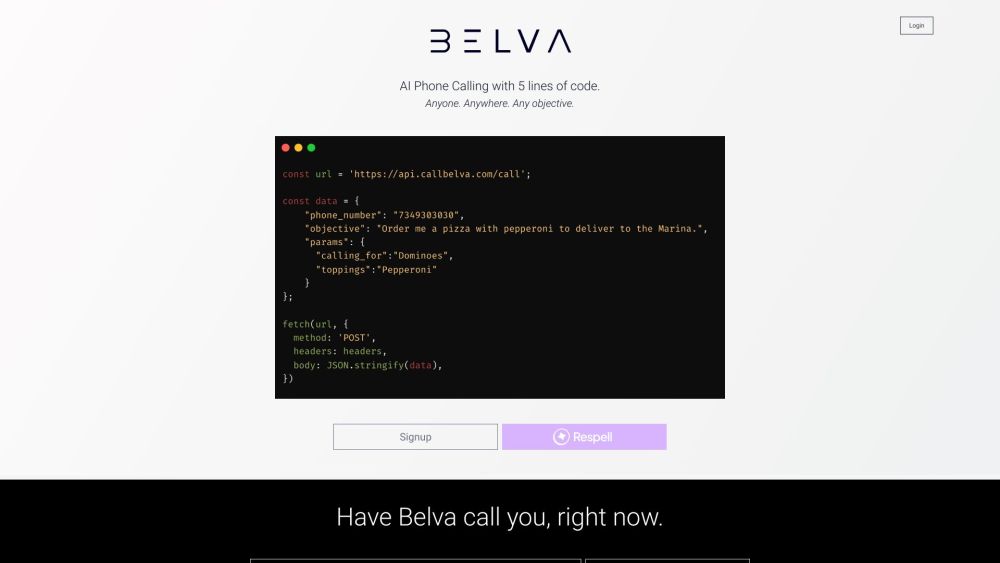
Belva é um Agente de Telefone AI avançado, projetado para aprimorar a eficiência da comunicação ao gerenciar diversas tarefas de maneira integrada.
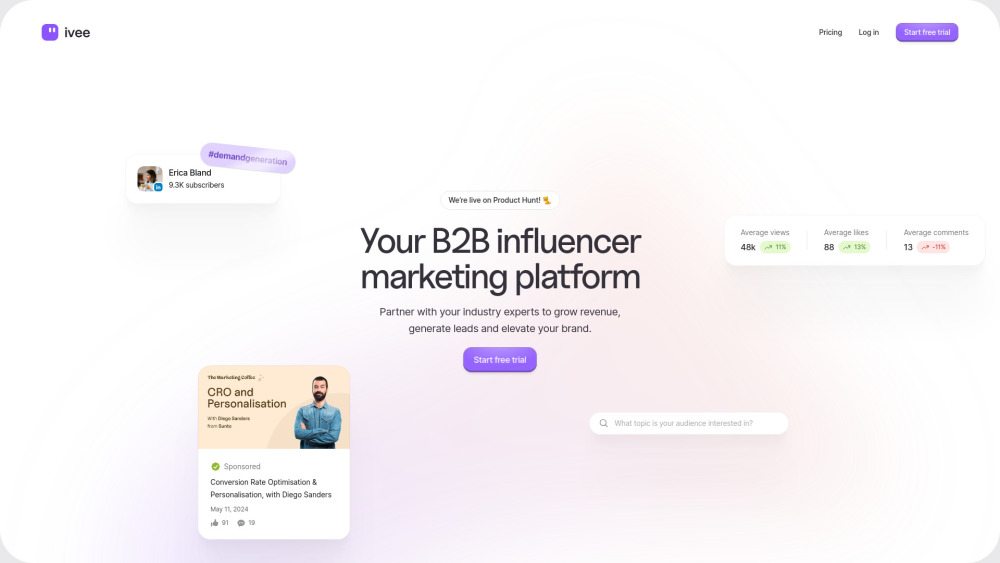
No panorama digital atual, as plataformas de marketing de influência B2B surgiram como ferramentas poderosas para empresas que buscam aumentar a visibilidade e credibilidade de sua marca. Ao se associar a líderes do setor e influenciadores, as empresas podem envolver de forma eficaz seu público-alvo, construir confiança e impulsionar conversões. Este artigo explora os principais benefícios e estratégias para aproveitar as plataformas de marketing de influência B2B, elevando seus esforços de marketing e alcançando um crescimento sustentável. Descubra como essas plataformas podem transformar sua abordagem para alcançar clientes e gerar leads em um mercado competitivo.
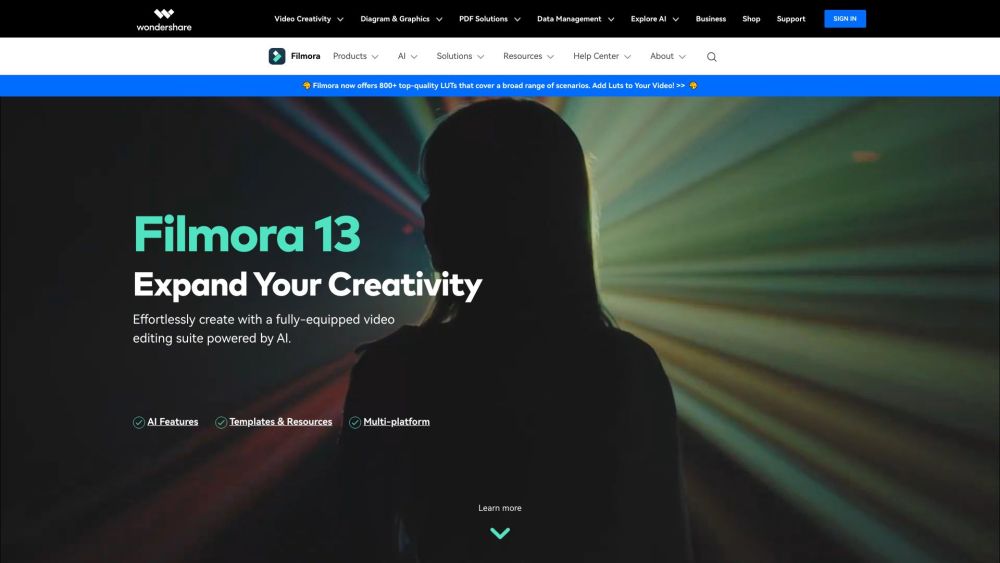
Edite vídeos com facilidade usando nossas ferramentas intuitivas. Descubra como a edição de vídeo pode simplificar seu processo de criação e aprimorar sua narrativa. Seja você um iniciante ou um criador experiente, dominar a edição de vídeo nunca foi tão fácil.
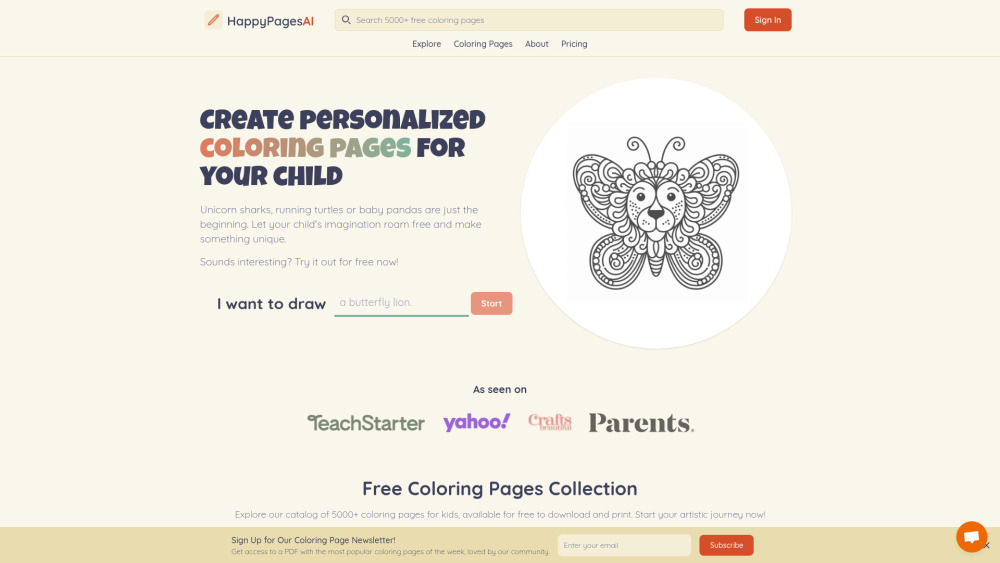
Transforme sua criatividade com nosso gerador de páginas para colorir com IA, projetado para criar páginas de coloração únicas e personalizadas, feitas especialmente para você. Seja você um fã de padrões intrincados ou ilustrações divertidas, nossa ferramenta inovadora permite que você libere seu talento artístico e desfrute de horas de diversão colorindo. Perfeito para crianças e adultos, este gerador é sua porta de entrada para designs personalizados que despertam a imaginação e proporcionam entretenimento sem fim.
Find AI tools in YBX
Related Articles
Refresh Articles