OpenAI представила «Рамочную программу готовности» для мониторинга и снижения рисков, связанных с ИИ.
Most people like
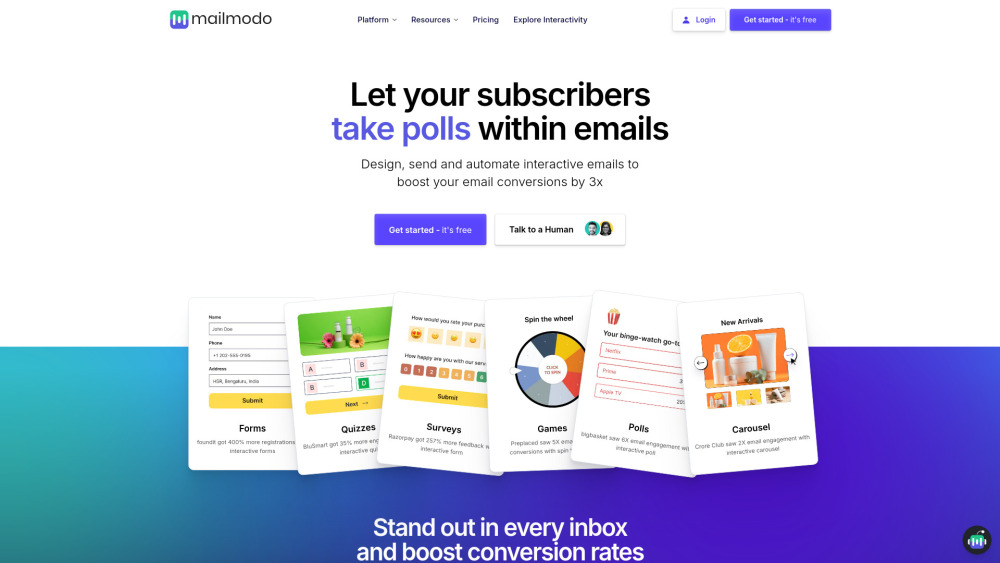
Откройте для себя возможности нашей платформы email-маркетинга, разработанной для создания интерактивных писем, которые существенно увеличивают вовлеченность аудитории. С нашими простыми в использовании инструментами и функциями вы сможете создавать визуально впечатляющие кампании, которые завораживают ваших подписчиков и приносят лучшие результаты.

Представляем Validator AI — мощную платформу, созданную для помощи предпринимателям, обеспечивая мгновенную поддержку и конструктивную обратную связь по их бизнес-идеям. С Validator AI воплотить ваши идеи в успешные проекты стало проще, чем когда-либо!

Wolfram|Alpha — это современный вычислительный движок, предназначенный для предоставления экспертных знаний по широкому спектру тем.

В все более цифровом мире студенты сталкиваются с уникальными вызовами на своем учебном пути. Наша платформа помощи с домашними заданиями, основанная на искусственном интеллекте, создана для предоставления своевременной и эффективной поддержки, помогая учащимся справляться с трудными предметами и углублять свои знания. Используя продвинутые алгоритмы и интеллектуальные ресурсы, мы даем возможность студентам уверенно достигать академических успехов. Независимо от того, испытываете ли вы трудности с математикой, науками или литературой, наша платформа предлагает персонализированные рекомендации, адаптированные под ваши нужды, обеспечивая, чтобы вы никогда не учились в одиночку. Примите будущее образования с нашим передовым решением!
Find AI tools in YBX
Related Articles
Refresh Articles