Stability AI запускает Stable Audio: Революционное решение для профессионалов в области звукового дизайна
Most people like
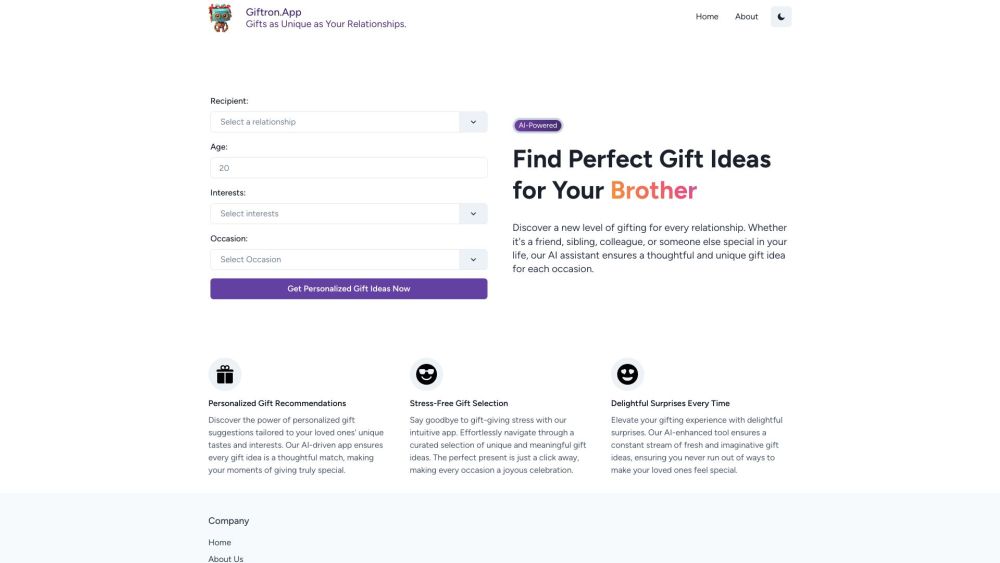
Найдите идеальный подарок, соответствующий уникальным предпочтениям вашего получателя. Будь то день рождения, юбилей или особый случай, наши персонализированные предложения подарков помогут вам выбрать идеальный вариант!

Akkadu предоставляет субтитры, сгенерированные ИИ в реальном времени, улучшая понимание видео и живых событий на нескольких языках. Эта инновационная технология позволяет зрителям легко следить за содержанием, обеспечивая гладкий и простой доступ к многоязычному контенту.
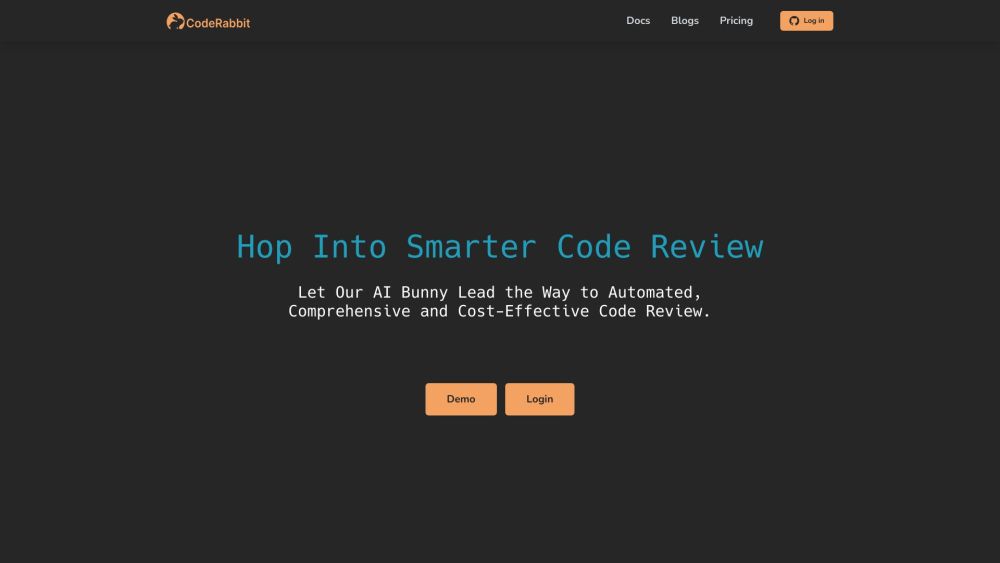
CodeRabbit — это инновационный инструмент на базе ИИ, созданный для ускорения ревизий кода за счет предоставления ценной информации, основанной на искусственном интеллекте.
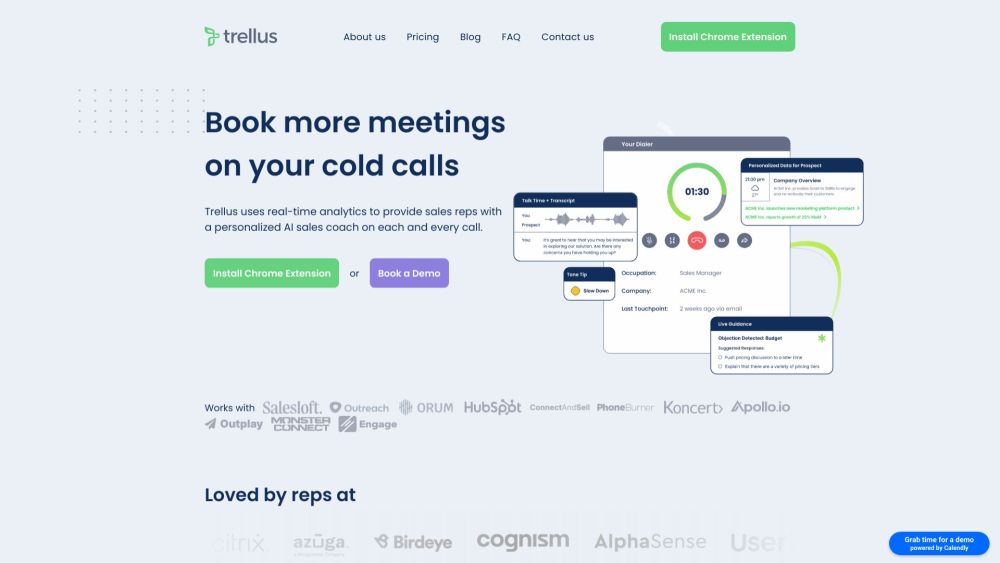
Представляем Trellus – инновационный инструмент на базе ИИ, созданный для персонализированного коучинга и аналитики в реальном времени, специально для торговых представителей во время холодных звонков. С Trellus улучшите свою стратегию холодных звонков и добейтесь успеха в продажах благодаря индивидуальным рекомендациям и аналитике.
Find AI tools in YBX
Related Articles
Refresh Articles