Stable Diffusion 3.0 представляет инновационную архитектуру диффузии для создания текстов в изображения с использованием искусственного интеллекта нового поколения.
Most people like
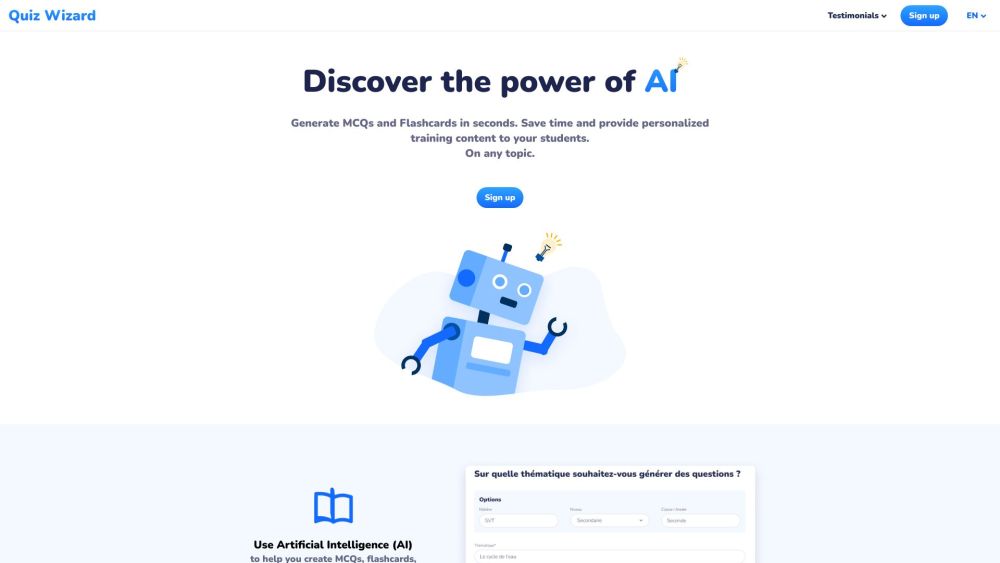
Quiz Wizard — это инновационная платформа на основе ИИ, разработанная для создания индивидуализированных вопросов с выбором ответа и специализированных учебных материалов.
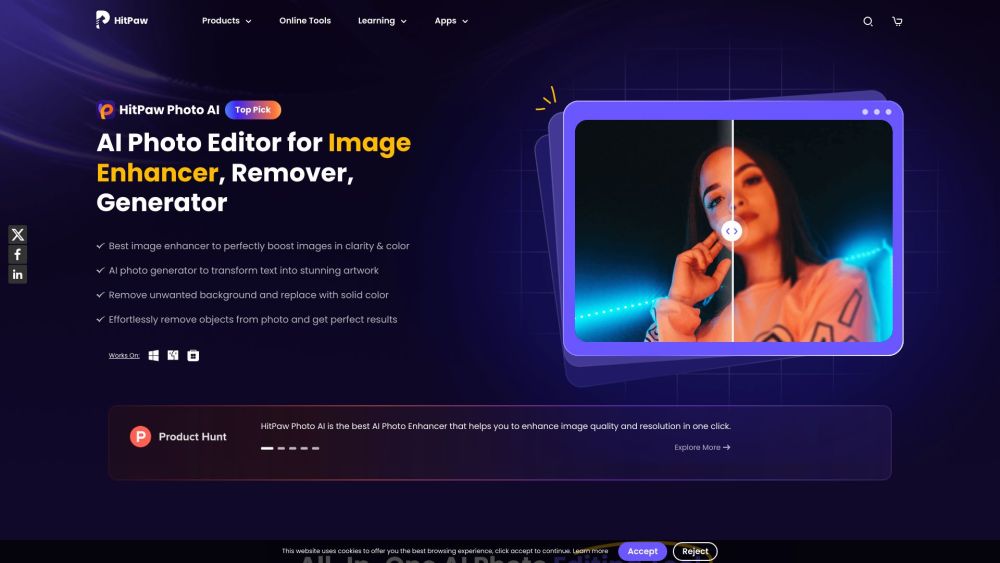
Откройте для себя передовое программное обеспечение для редактирования фотографий на основе ИИ, которое революционизирует ваш опыт фотографии. С его продвинутыми функциями и интуитивно понятными инструментами это мощное ПО поднимает ваши изображения на профессиональный уровень, делая улучшение, ретушь и трансформацию ваших фотографий проще простого. Идеально подходит для фотографов любого уровня подготовки, оно сочетает в себе искусственный интеллект и творческую гибкость, чтобы воплотить вашу визию в жизнь.
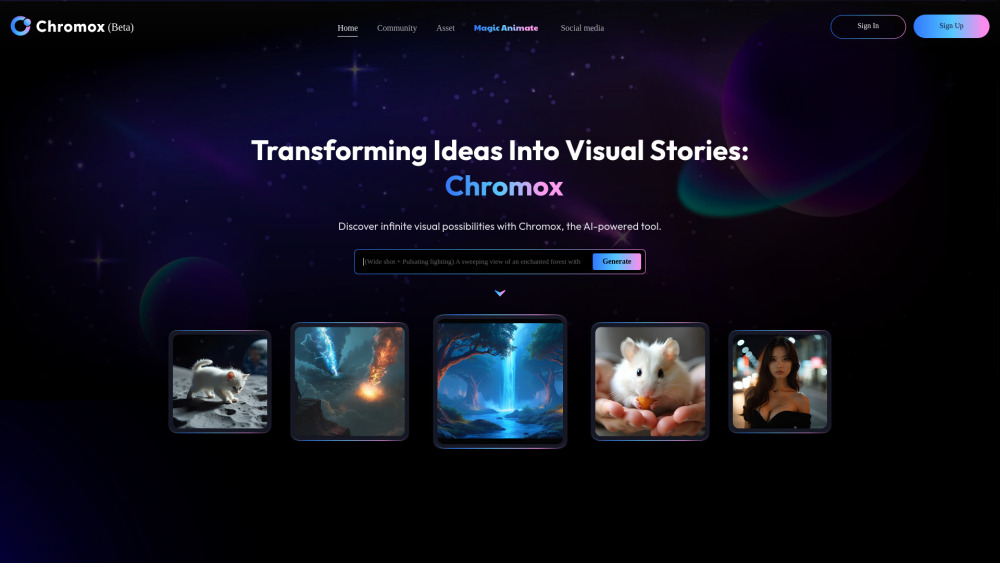
Откройте для себя лучшие бесплатные альтернативы OpenAI Sora для создания увлекательных видео с использованием ИИ.
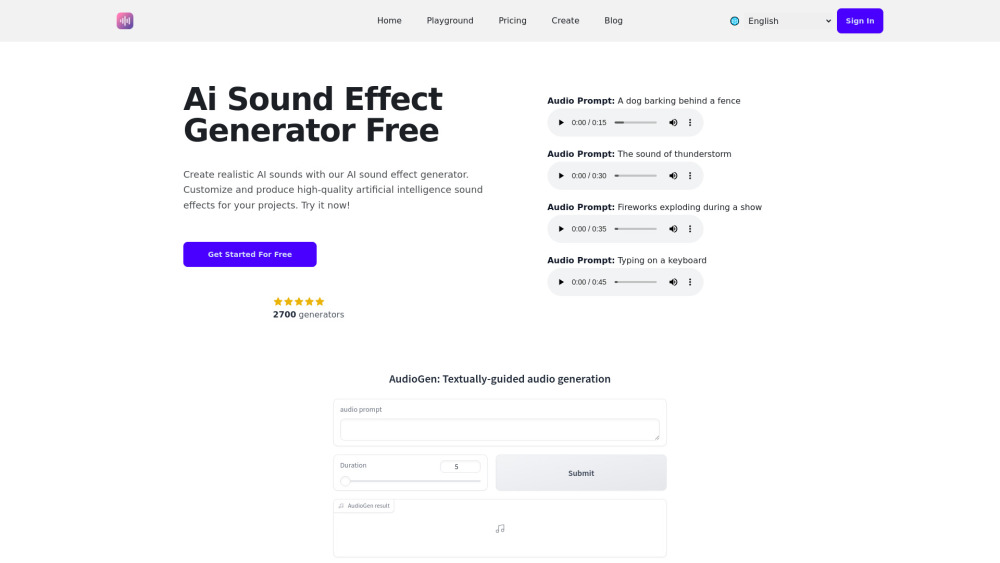
Улучшить ваши аудиопроекты стало проще простого с нашим генератором звуковых эффектов на основе ИИ, созданным для генерации множества уникальных аудиоэффектов. Освобождайте безграничные творческие возможности и поднимайте свои звуковые пейзажи с помощью этого мощного инструмента, идеально подходящего для кинематографистов, разработчиков игр и контент-креаторов. Узнайте, как технологии ИИ могут преобразить ваш аудиоопыт уже сегодня!
Find AI tools in YBX
Related Articles
Refresh Articles