aiOla представляет молниеносную модель распознавания речи 'Multi-Head', которая превосходит OpenAI Whisper.
Most people like
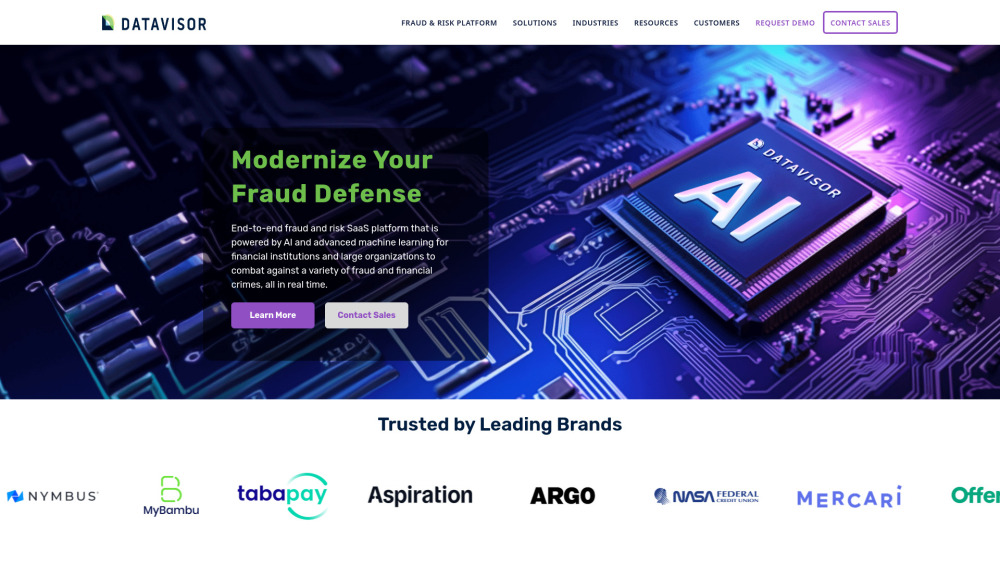
Представляем платформу управления мошенничеством на основе ИИ, разработанную специально для предприятий, чтобы эффективно минимизировать риски и защищать их активы. Это инновационное решение использует передовые алгоритмы для обнаружения и предотвращения мошеннических действий, обеспечивая безопасную среду для ваших бизнес-операций.

В современном цифровом пространстве создание увлекательного контента, который находит отклик у читателей, стало важнее, чем когда-либо. Человечность в контенте, созданном ИИ, не только улучшает его читаемость, но и способствует искренней связи с аудиторией. Интегрируя понятный язык и разговорный стиль, мы можем превратить техническую информацию в доступные нарративы. Такой подход не только привлекает внимание, но и способствует более глубокому пониманию, выделяя ваш контент на фоне множества информации. Освойте искусство человечности в контенте ИИ, чтобы повысить качество вашего письма и эффективно взаимодействовать с читателями.
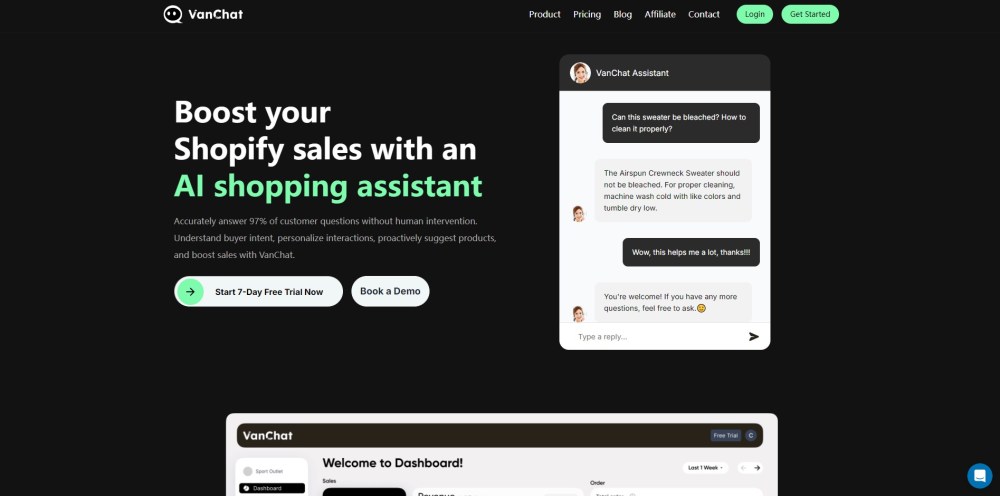
Узнайте, как искусственный интеллект в виде помощника для Shopify может преобразить взаимодействие с клиентами, увеличивая вовлеченность и стимулируя продажи. Используя современные технологии, этот инновационный инструмент улучшает процесс покупок, делая его плавным и персонализированным для каждого пользователя. Поднимите свой магазин Shopify на новый уровень с помощником, который понимает потребности клиентов.

Лебег: мощный маркетинговый инструмент для интернет-магазинов, максимизирующий ROI с помощью глубокого анализа данных.
Find AI tools in YBX
Related Articles
Refresh Articles