Исследователи Раскрывают Потенциал ChatGPT
Most people like
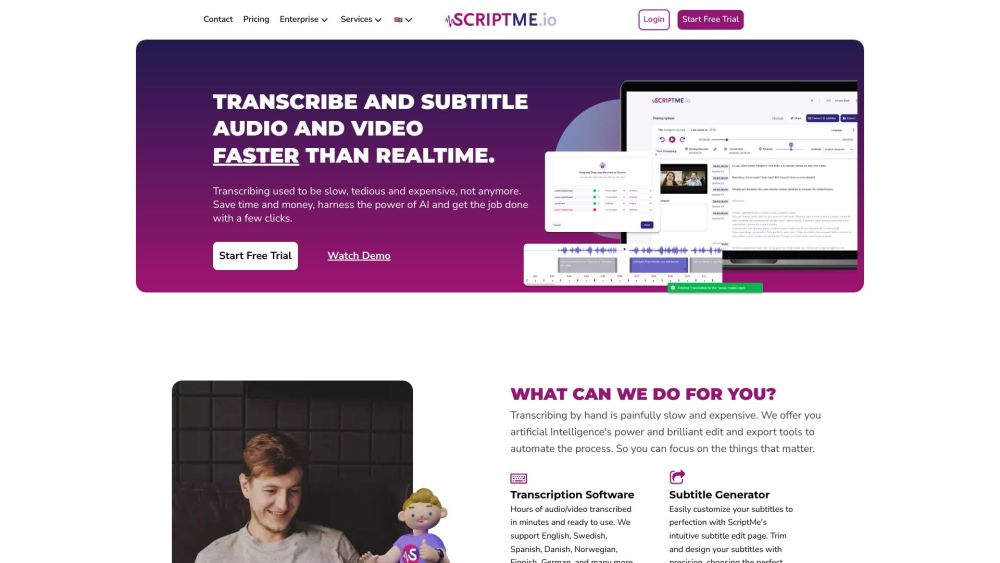
ScriptMe предлагает быстрые и точные услуги транскрибации и субтитрования на различных языках, гарантируя высококачественные результаты, адаптированные под ваши нужды.
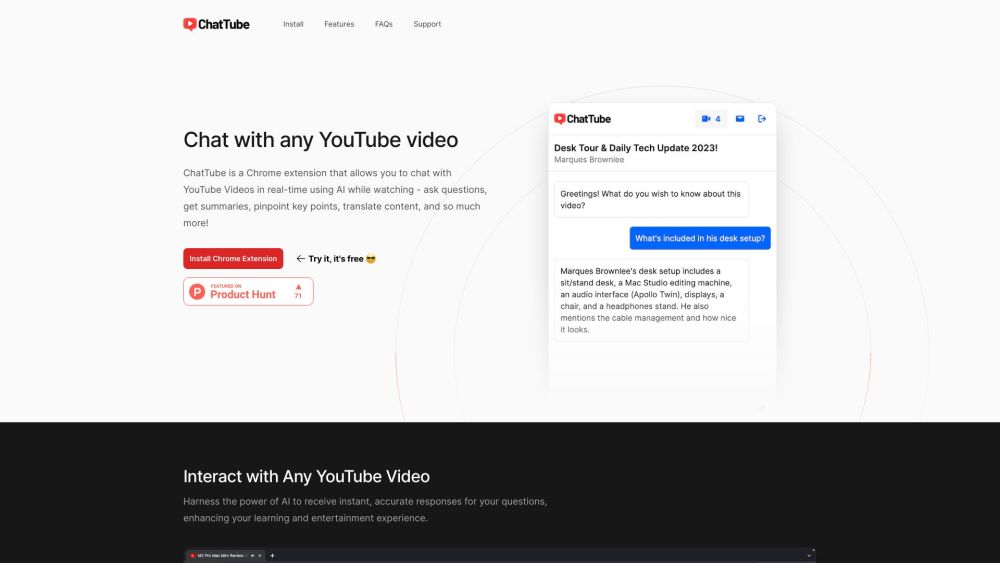
ChatTube — это инновационная платформа на базе ИИ, которая позволяет пользователям взаимодействовать с видео на YouTube как никогда ранее. С такими функциями, как интерактивные вопросы и ответы, а также краткие резюме, ChatTube улучшает ваш опыт просмотра, делая информацию более доступной и увлекательной.
WordHero — это продвинутый инструмент ИИ для написания, который помогает вам создавать качественный контент быстро и без усилий.
Представляем Генератор AI для создания видео из текста: ваш идеальный инструмент для анонимных авторов
Разблокируйте свою креативность с нашим инновационным Генератором AI для создания видео из текста, специально разработанным для анонимных создателей контента. Превращайте свои письменные идеи в захватывающие видео без усилий, улучшая ваше повествование и охват. Подходит для тех, кто ценит конфиденциальность, оставаясь при этом в центре внимания; наша удобная платформа сочетает передовые технологии с креативностью, позволяя вам увлекать аудиторию без появления на экране. Откройте для себя будущее создания контента, где ваши слова оживают визуально!
Find AI tools in YBX
Related Articles
Refresh Articles