Предупреждение от генерального директора YouTube к OpenAI: Риски нарушения правил при обучении ИИ-моделей на видеоконтенте
Most people like
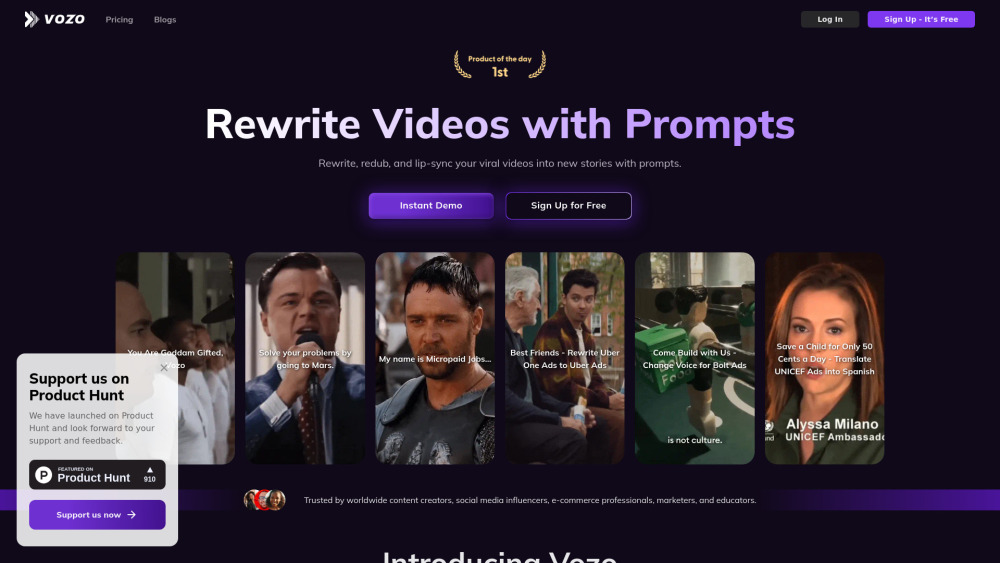
Раскройте потенциал вашего видеоконтента с помощью генератора видео на основе ИИ, который упрощает и улучшает процесс преобразования видео. Независимо от того, хотите ли вы создать увлекательные маркетинговые материалы, динамичные клипы для социальных сетей или захватывающие обучающие видео, этот инновационный инструмент позволяет вам легко получать высококачественные результаты. Откройте для себя будущее видеопродукции и позвольте вашим креативным идеям воплотиться в жизнь с помощью ИИ.

Ведите живые беседы с вашими любимыми AI-моделями, включая LLaMA, Alpaca и GPT4All, на LlamaChat. Ощутите интуитивные взаимодействия и узнайте возможности этих продвинутых чат-ботов уже сегодня!
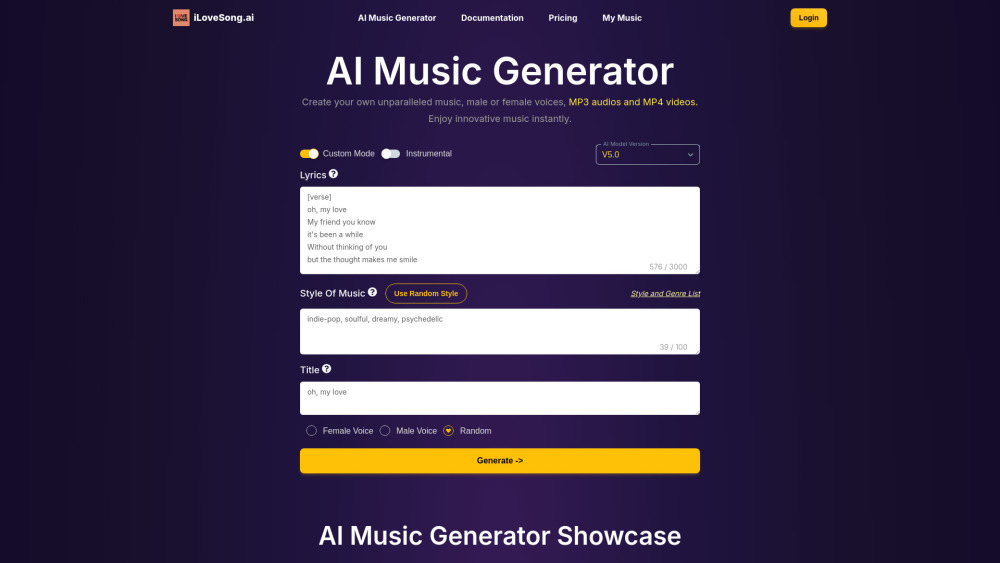
Откройте для себя возможности нашего генератора музыки на базе ИИ, созданного для того, чтобы помочь вам создавать и скачивать уникальную, кастомизированную музыку, соответствующую вашим нуждам. Независимо от того, ищете ли вы оригинальные композиции для проекта, фоновые треки для видео или персонализированные звуковые пейзажи, наша платформа упрощает процесс создания музыки и делает его доступным для всех. Начните создавать свои мелодии уже сегодня!

Откройте для себя уникальную коллекцию агрегаторов ИИ, созданных для повышения вашей продуктивности. Независимо от того, нужна ли вам помощь в написании текстов, анализе данных или творческих проектах, эти платформы предлагают лучшие инструменты для удовлетворения ваших потребностей. Изучите наш тщательно подобранный список ведущих ресурсов ИИ, доступных сегодня, и усовершенствуйте свой рабочий процесс с помощью передовых технологий на кончиках пальцев.
Find AI tools in YBX
Related Articles
Refresh Articles