Изучение нового AI-модели Apple 'MM1': функции, приложения и инновации.
Most people like
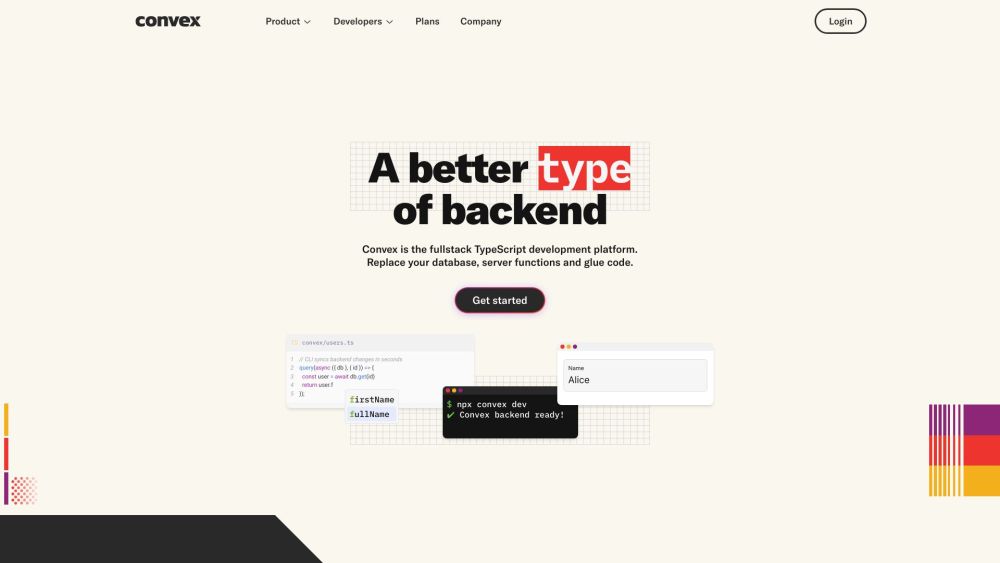
Откройте для себя возможности платформы полного стека на TypeScript, специально разработанной для создания высоко отзывчивых приложений. Благодаря своим надежным функциям эта платформа позволяет разработчикам без труда создавать динамичные и интерактивные пользовательские интерфейсы, улучшая как фронтенд, так и бэкенд разработку. Раскройте потенциал реактивного программирования с эффективным и продуктивным фреймворком на TypeScript!
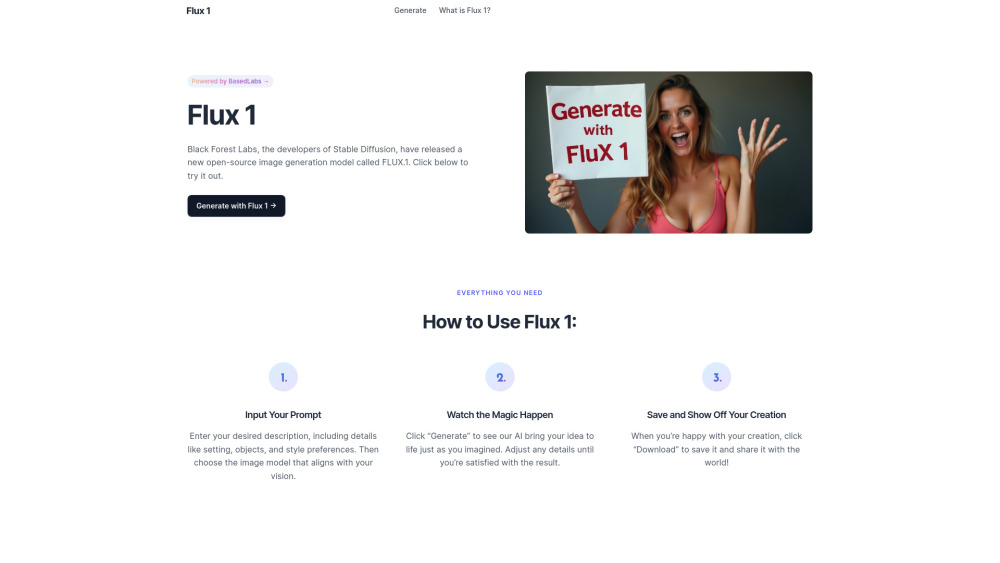
Генератор изображений ИИ: Создавайте потрясающие визуалы быстро и без усилий
Откройте для себя наш передовой генератор изображений ИИ, созданный для быстрого производства качественных визуалов, соответствующих вашим потребностям. Будь вы маркетологом, дизайнером или создателем контента, этот инструмент позволяет вам генерировать захватывающие изображения за считанные секунды, улучшая ваши проекты без потери качества. Раскройте свой творческий потенциал и оптимизируйте свой рабочий процесс с нашим инновационным решением.

Создавайте профессиональные резюме без усилий с помощью CVBee.ai — генератора резюме на основе ИИ всего за несколько минут. Поднимите свои заявки на работу и улучшите карьерные перспективы уже сегодня!
Find AI tools in YBX
Related Articles
Refresh Articles