人工智慧能與人類數據科學家競爭嗎?OpenAI的新基準測試將揭示答案。
Most people like

在當今的數位環境中,有效的社交媒體管理對於希望提升線上存在感的企業至關重要。一個統一的社交媒體管理平台使品牌能夠整合其社交媒體活動,確保在各個渠道與受眾之間進行無縫互動。通過利用先進的工具和洞察,企業可以優化其策略,增強溝通,並推動可衡量的成果。了解這樣的平台如何變革您的社交媒體策略,並提升品牌在競爭環境中的能見度。
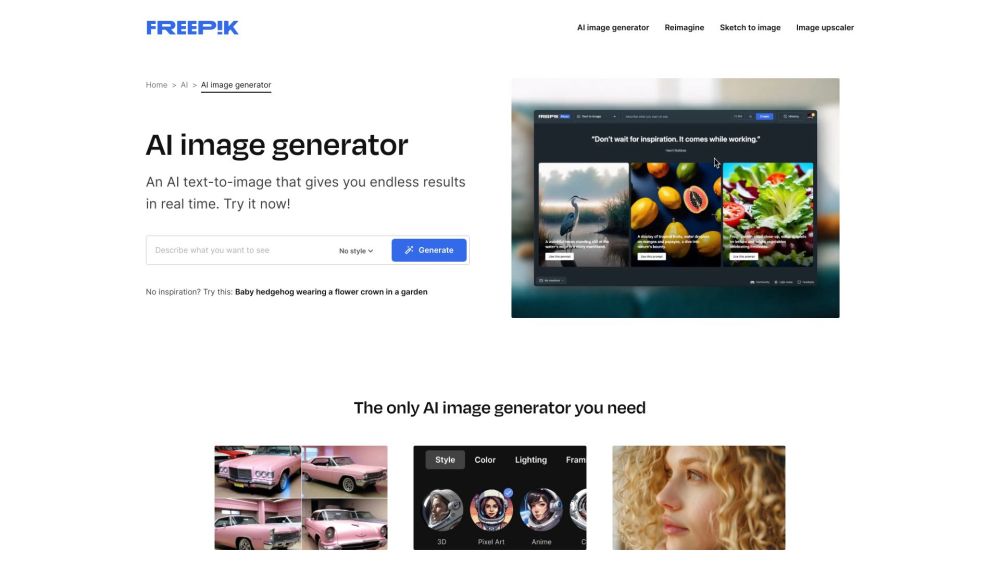
在當前的數位環境中,實時 AI 圖像生成器的力量成為藝術家、設計師及任何希望輕鬆創造驚人視覺效果的人的革命性工具。這些創新的應用程式利用先進的算法和機器學習,能瞬間生成高品質圖像,將想法轉化為視覺傑作。無論是專業項目還是個人創作,實時 AI 圖像生成為無限創意和靈感的世界打開了大門。
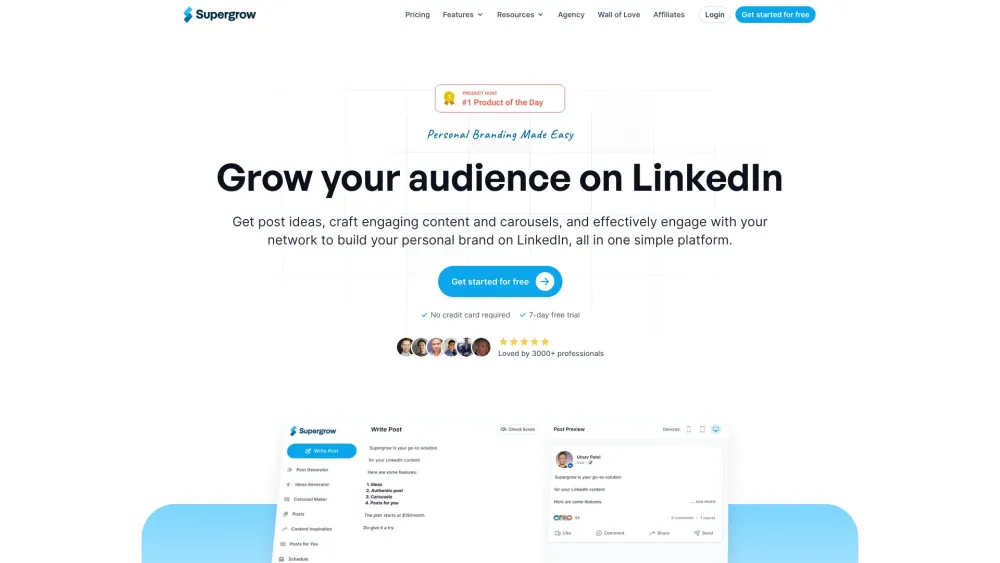
提升您的個人品牌於LinkedIn:成長與成功的策略
利用LinkedIn的力量,有效地建立和擴展您的個人品牌。在當今競爭激烈的職場環境中,建立強大的線上存在感對於把握機會和與行業領袖建立聯繫至關重要。無論您是在尋求新的職業前景,還是希望提升您的可信度,本指南提供切實可行的策略,幫助您在LinkedIn中脫穎而出並蓬勃發展。

在這個日益數位化的世界中,學生在學業旅程中面臨著獨特的挑戰。我們的AI輔助作業平台旨在提供及時而有效的支持,幫助學習者應對困難科目並增進理解。通過運用先進的算法和智能資源,我們賦予學生自信,助他們邁向學業成功。不論你在數學、科學還是文學上遇到困難,我們的平台都能提供量身訂製的個性化指導,確保你不再孤單學習。擁抱教育的未來,與我們的尖端解決方案同行!
Find AI tools in YBX
Related Articles

Refresh Articles