AI 模型自評安全性:OpenAI 最新對齊研究的洞見
Most people like
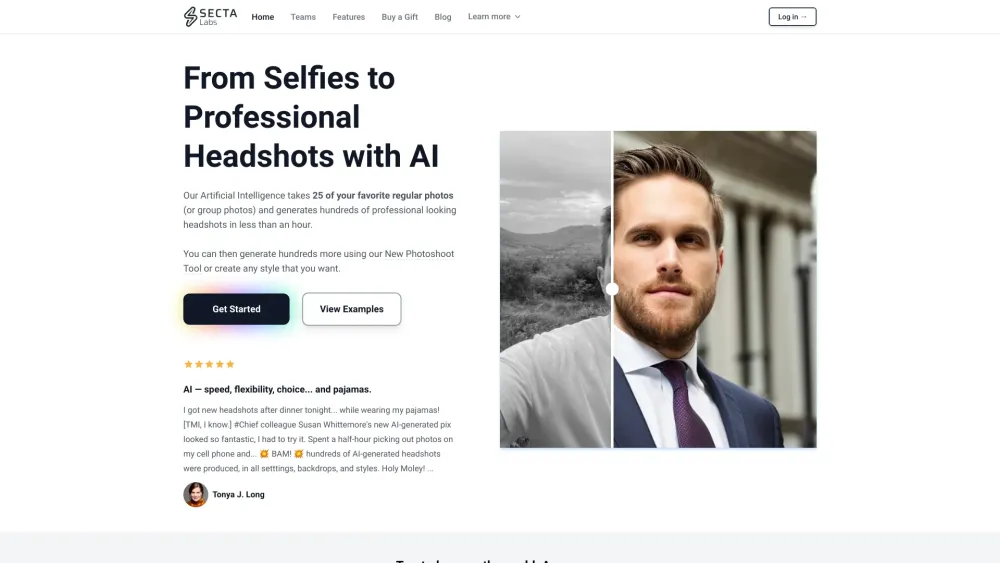
在當今的數位世界,良好的第一印象至關重要。 AI 生成的專業頭像不僅提升您的線上形象,還傳達出專業性和親和力。這些頭像利用先進的人工智慧技術,專為個人和企業的獨特風格及品牌需求而打造。了解如何擁抱 AI 生成的影像,能夠改變您的個人和專業品牌,讓您在競爭激烈的環境中脫穎而出。

在當今競爭激烈的環境中,有效的全球專利檢索與分析在推動創新和保護知識產權方面扮演著至關重要的角色。透過系統性地收集和檢視來自世界各地的專利數據,企業和研究人員能夠識別趨勢、揭示競爭情報並做出明智的決策。這一過程不僅提升了策略規劃,還藉由緊跟技術進步和市場變化促進增長。加入我們,探索導航全球專利資訊複雜性所需的基本方法和工具,以助力您的創新策略。
Find AI tools in YBX
Related Articles
Refresh Articles