Anthropic推出1.5萬美元獎金,邀請駭客協助增強AI安全性
Most people like
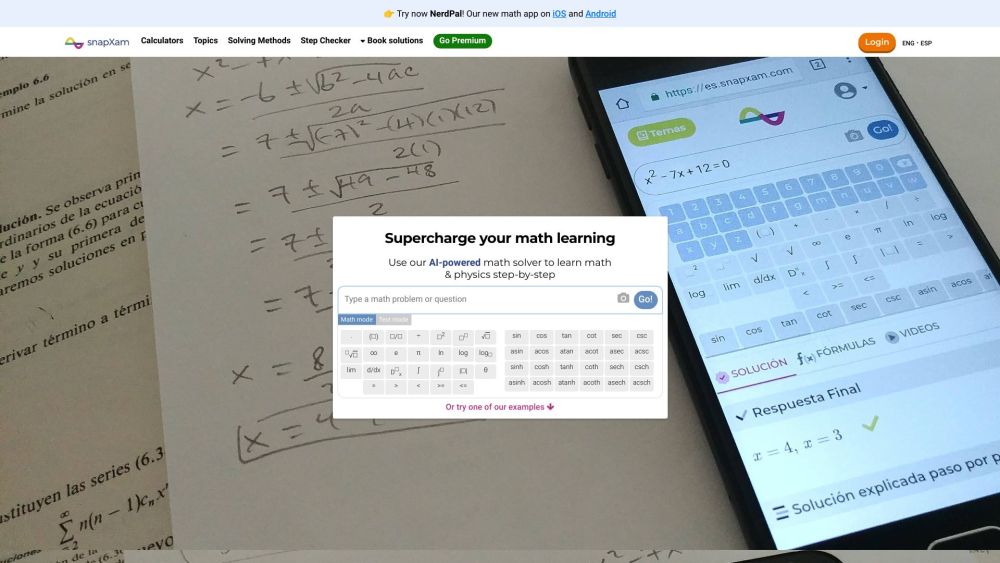
介紹人工智慧驅動的數學和物理輔導器:您終極的學習夥伴
透過我們先進的人工智慧輔導平台,釋放您在數學和物理方面的潛能。這款設計用以提供個性化協助的人工智慧輔導器,會根據您的學習風格進行調整,幫助您掌握挑戰性的概念並在學業上取得優異成績。體驗量身定制的課程、即時反饋,及引人入勝的練習題,讓複雜主題變得易於理解。探索教育的未來,體驗這款改變您學習數學和物理方式的人工智慧輔導器!
提升您對人工智慧驅動的客戶反饋分析的理解。探索利用人工智慧如何改變企業收集、解讀與應對客戶洞察的方式。揭示增強客戶滿意度及通過創新反饋機制推動增長的寶貴策略。擁抱以數據驅動的決策未來,搭配尖端的人工智慧技術。
Find AI tools in YBX
Related Articles

Refresh Articles