Meta推出Megalodon大型語言模型,挑戰Transformer架構
Most people like

在當今快速變化的工作環境中,促進員工參與對於組織的成功至關重要。利用人工智慧驅動的員工參與平台,能夠透過先進技術提升團隊的動力、合作及整體生產力。透過數據驅動的洞察力和個性化策略,這一創新解決方案使企業能夠打造更具連結性和動力的勞動力,最終提升績效和留才率。探索以人工智慧為核心的策略如何改變您組織的參與模式,並促成一個蓬勃發展的工作文化。
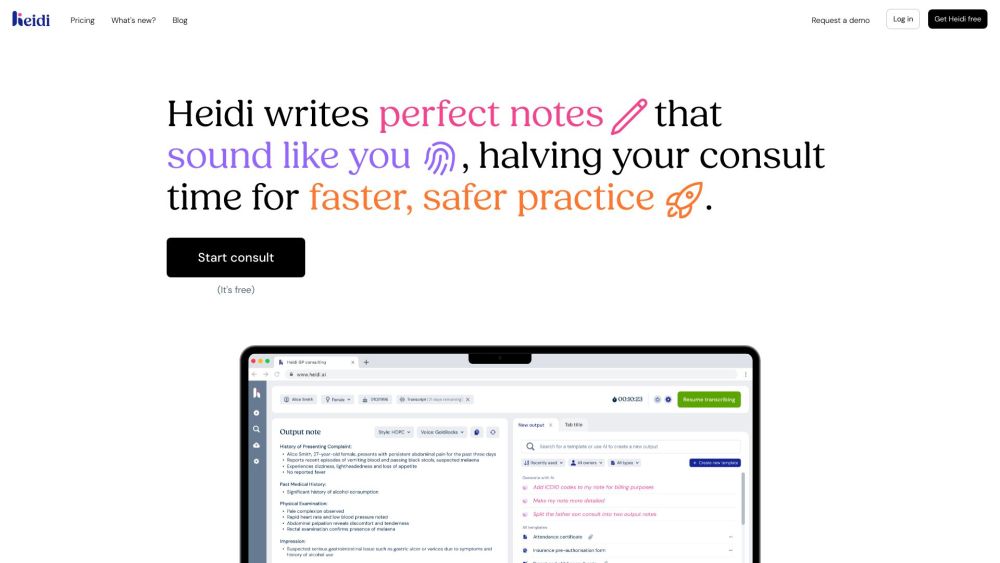
在當今快速變化的醫療環境中,臨床醫師常常因行政工作而感到不堪重負,無法專注於病患照護。AI書記技術應運而生,成為改變遊戲規則的方案,旨在簡化文檔處理並提高效率。通過智能轉錄和數據輸入解決方案,AI書記能夠為臨床醫師節省數天寶貴時間,使他們能夠專注於真正重要的事情:提供卓越的病患照護。
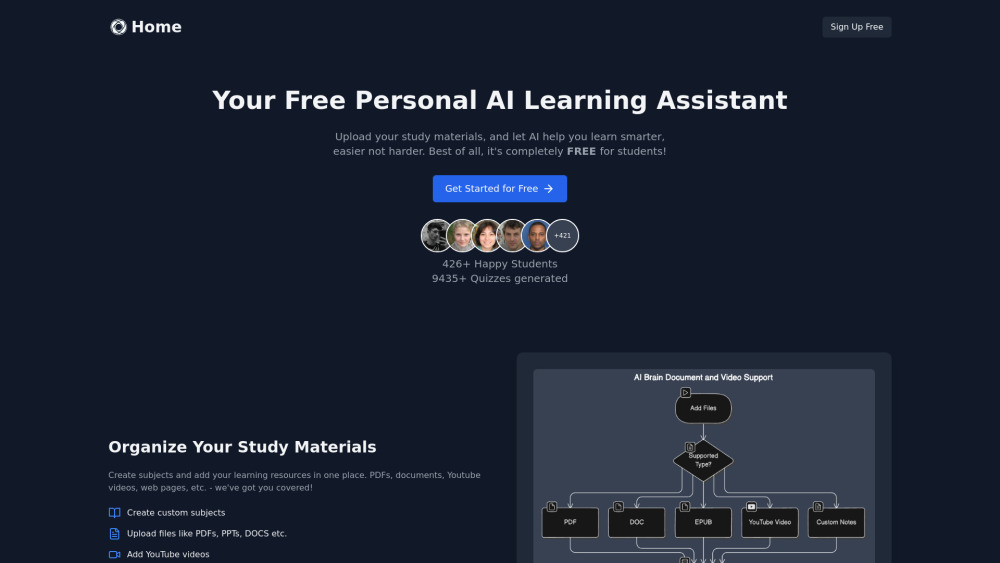
您是否在努力整理學習材料,或尋找創新的方法準備考試?我們的AI學習助手將為您提供幫助!這款智能工具不僅能有效地整理您的學習資源,還能生成定制化的測驗,以加強您的學習。採用更智慧的學習方式,提升您的考試表現,讓這個尖端的AI解決方案伴您左右。
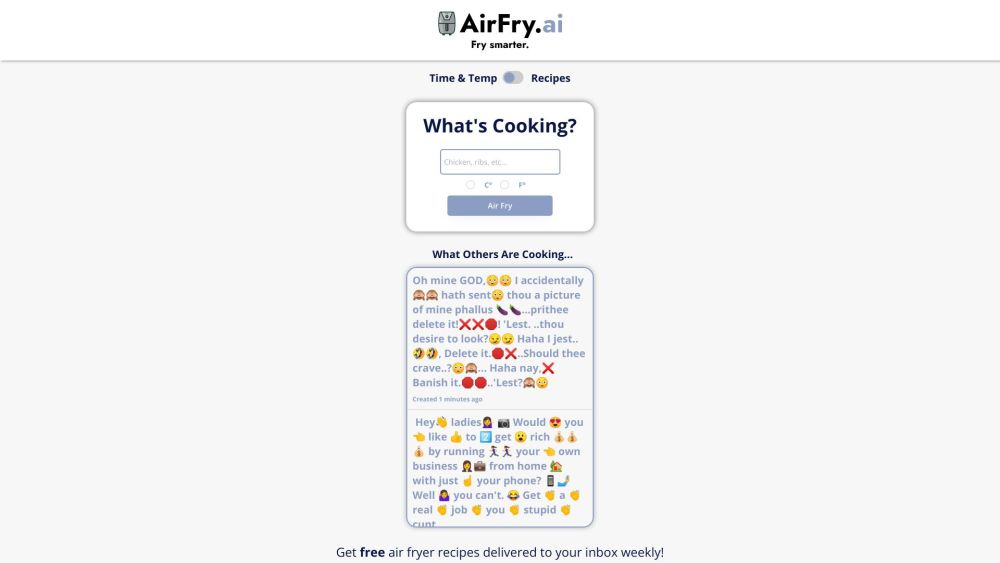
Find AI tools in YBX
Related Articles
Refresh Articles