Sora 對於複雜視覺內容的處理:揭開時空修補的祕密
Most people like
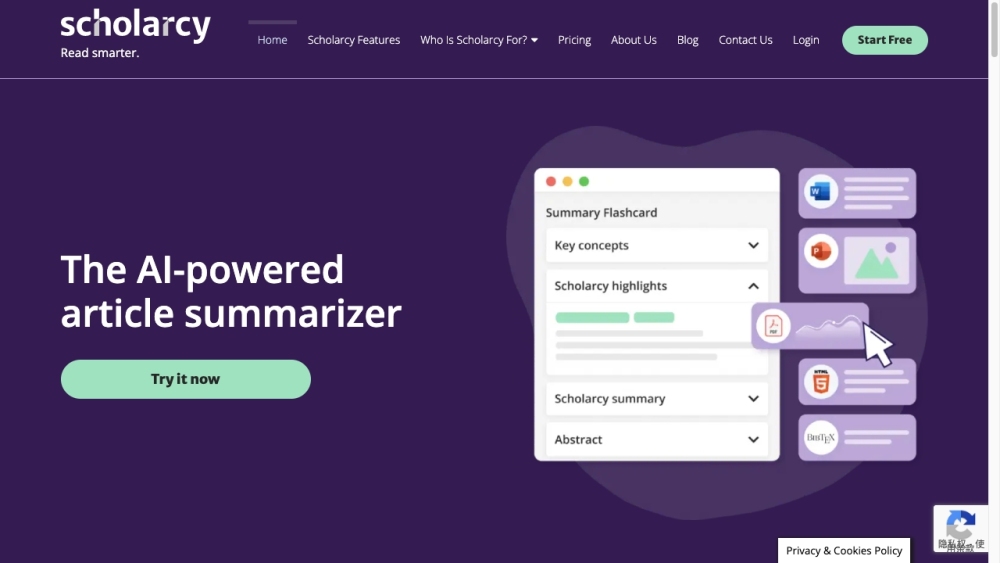
Scholarcy 是一款創新的 AI 工具,旨在將文章轉換為精簡的摘要卡片,使評估變得快速高效。透過 Scholarcy,釋放精簡學習的力量,讓您輕鬆掌握重要資訊,一目了然。


Find AI tools in YBX
Related Articles

Refresh Articles