開源 AI 與封閉源 AI:為什麼數據質量和適應性至關重要
Most people like
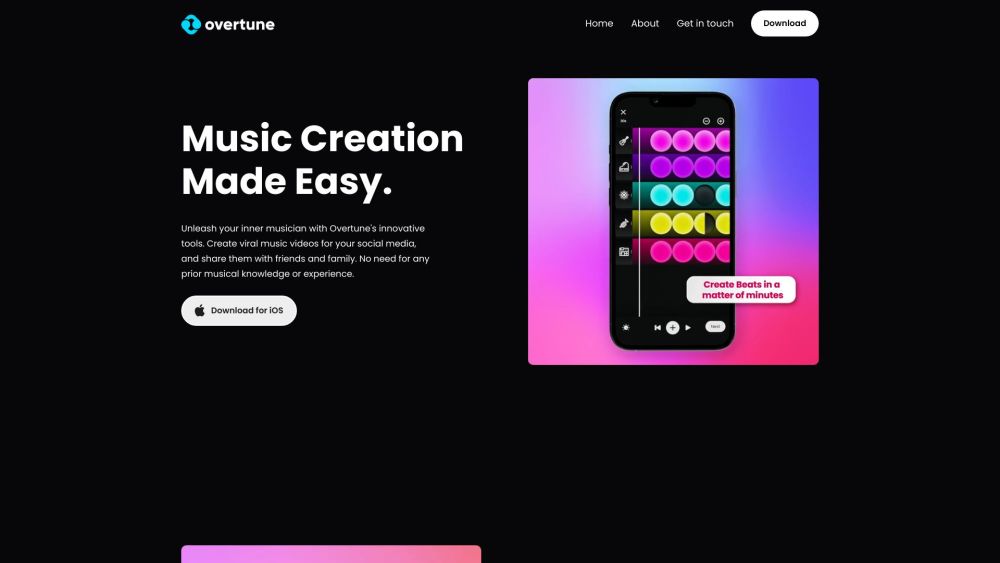
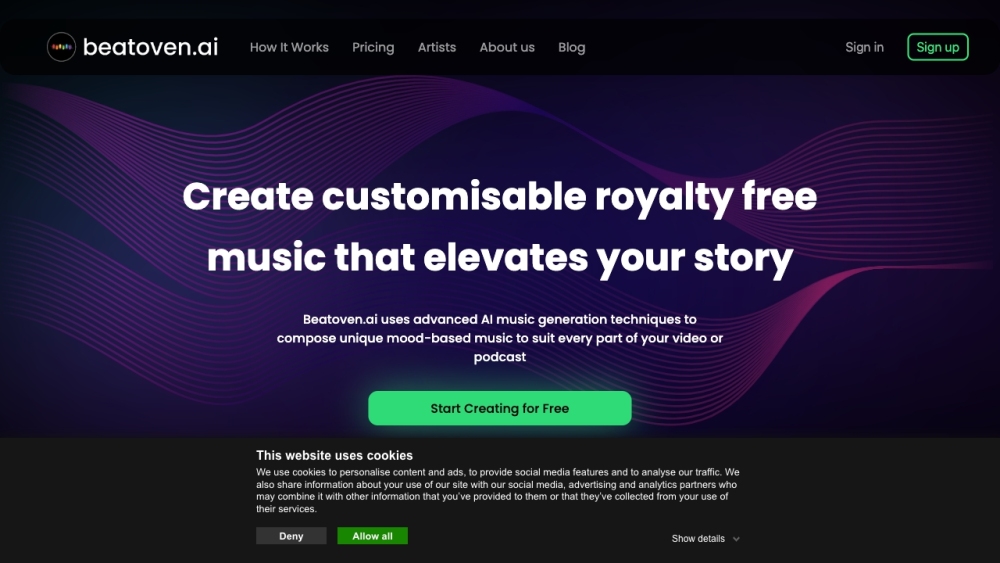
發現 Beatoven.ai,這款專為內容創作者設計的創新 AI 音樂生成器。使用 Beatoven.ai,您可以輕鬆創作獨特的情緒音樂,提升您的項目,增強您的敘事,並吸引您的觀眾。
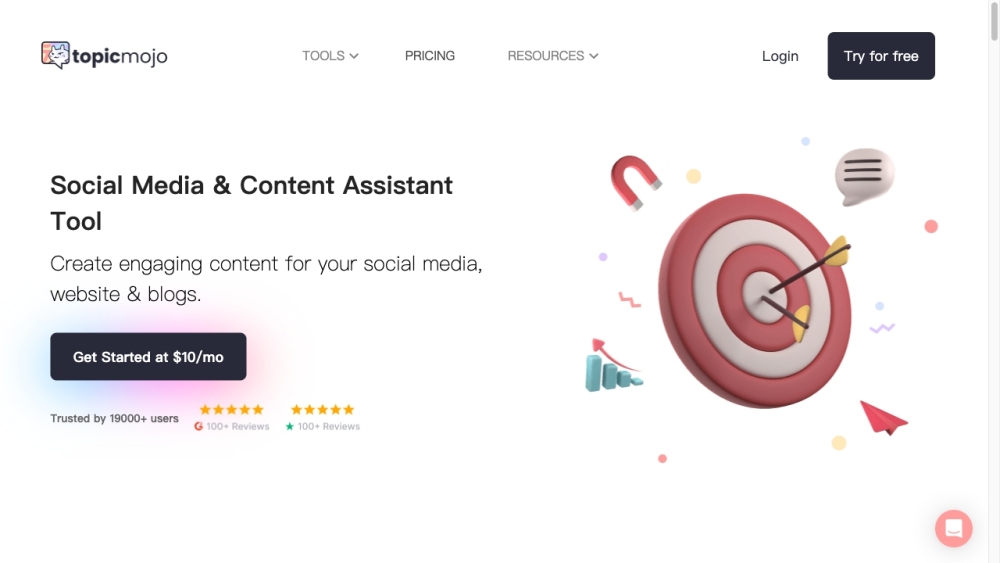
Topic Mojo 是一款強大的研究工具,旨在為內容創作者提供有價值的見解,幫助他們創作引人入勝且相關的內容。透過深入的數據分析,Topic Mojo 使使用者能夠做出明智的決策,從而提升他們的內容創作過程。
Find AI tools in YBX
Related Articles

Refresh Articles