亚马逊AWS发布雄心勃勃的生成AI新动态,欲与微软竞争
Most people like
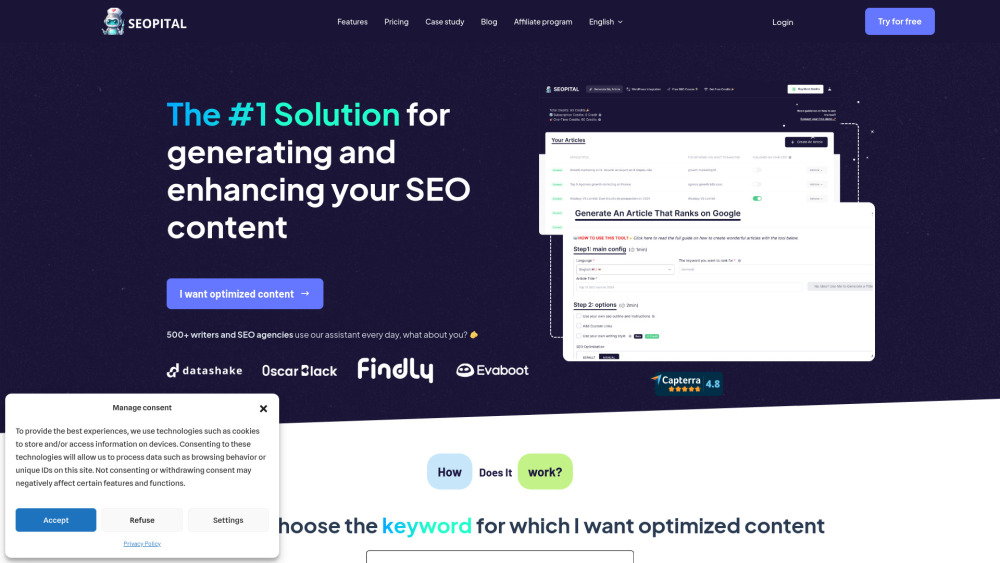
SEO AI写作助手:提升内容排名的利器
在当今数字时代,高质量的内容是网站成功的关键。SEO AI写作助手旨在帮助创作者生成优化的文章,从而提高搜索引擎排名,增强在线可见性。无论您是博主、营销人员,还是企业主,这款智能工具都能为您提供精准的关键词建议和内容结构指导,确保您的作品不仅吸引读者,还能在搜索引擎中脱颖而出。让我们一起探索如何借助SEO AI写作助手,创作出更具竞争力的高排名内容!
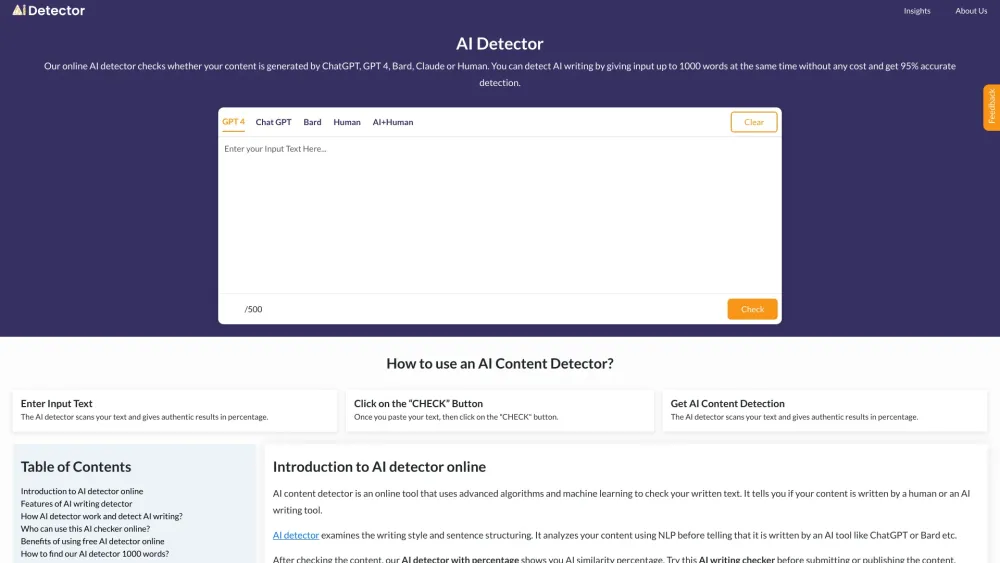
引入先进算法以实现高效的AI检测。通过结合最新技术,能够有效提高检测准确性和速度,从而在复杂的数据环境中迅速识别潜在问题。这一创新方法不仅优化了检测流程,还为各行业提供了可靠的解决方案,助力企业在数字化转型中保持竞争优势。
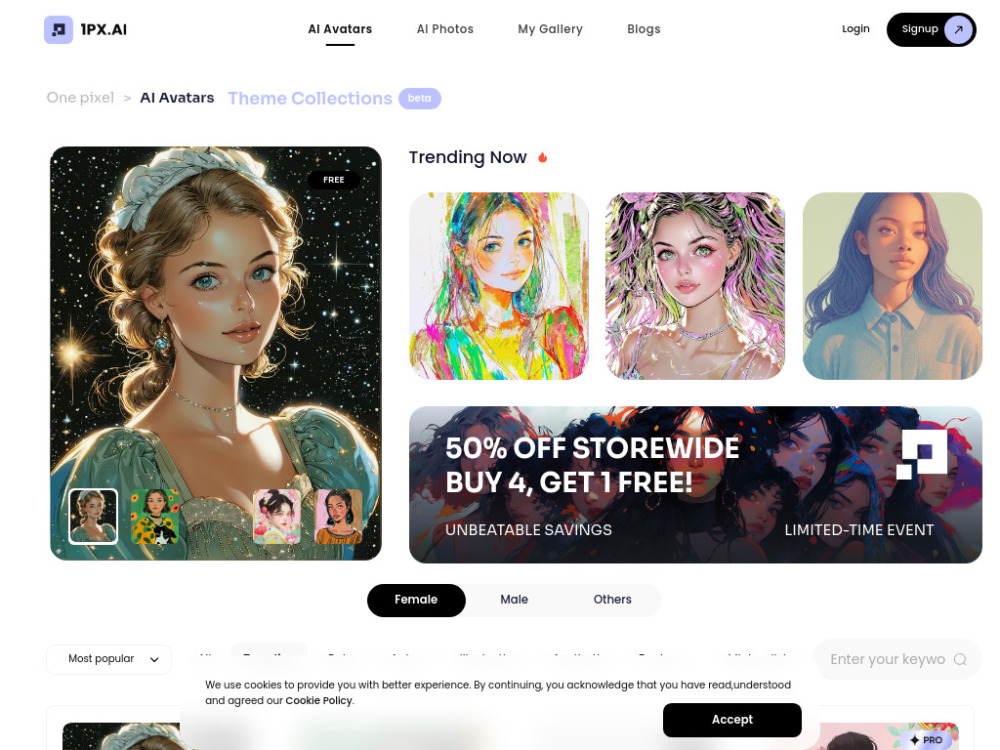
在数字艺术和创造性表达迅速发展的今天,AI肖像生成器正变得越来越受欢迎。这些智能工具利用先进的算法和深度学习技术,能够生成惊艳的肖像,无论是现实主义风格还是超现实主义作品。从艺术家到企业,越来越多的人们正在利用这些工具来实现创意灵感和提升视觉内容的质量。本文将深入探讨AI肖像生成器的工作原理、应用场景以及它们如何革新传统艺术创作的方式。

Find AI tools in YBX
Related Articles
Refresh Articles