据报道,Reddit与谷歌达成6000万美元合作伙伴关系,以提升人工智能工具
Most people like
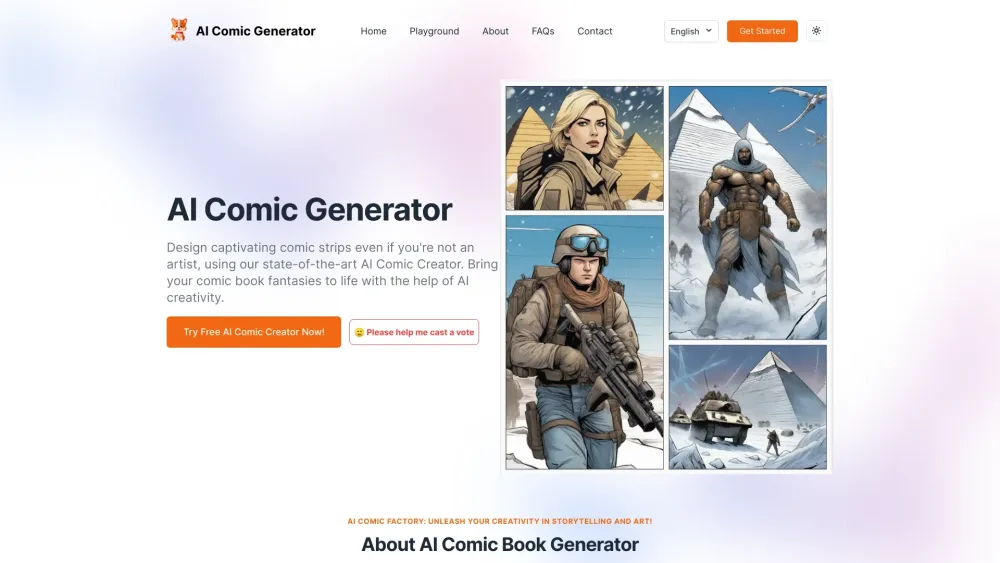
创造漫画书的新时代:使用AI技术让创作更简单、更高效。随着人工智能的快速发展,越来越多的创作者开始利用AI来激发灵感、绘制插图和编写故事。这不仅降低了创作的门槛,也为漫画艺术家和爱好者打开了全新的可能性。加入我们,一起探索如何通过AI赋能您的漫画创作旅程!

研究人员的人工智能工具与出版服务:提升研究效率与成果可见性
在当今快速发展的学术界,研究人员面临着竞争激烈的挑战。为了提高研究效率并确保研究成果得到广泛传播,许多先进的人工智能工具和专业出版服务应运而生。通过智能化的数据分析、文献管理和出版支持,这些服务不仅能帮助研究人员节省时间,还能提升其研究成果的影响力。探索这些新兴工具的潜力,将为研究人员在不断演变的学术环境中提供更强的竞争优势。
Find AI tools in YBX
Related Articles
Refresh Articles