استخدام Apple لأجهزة Google في تدريب نموذج الذكاء الاصطناعي الخاص بها
Most people like
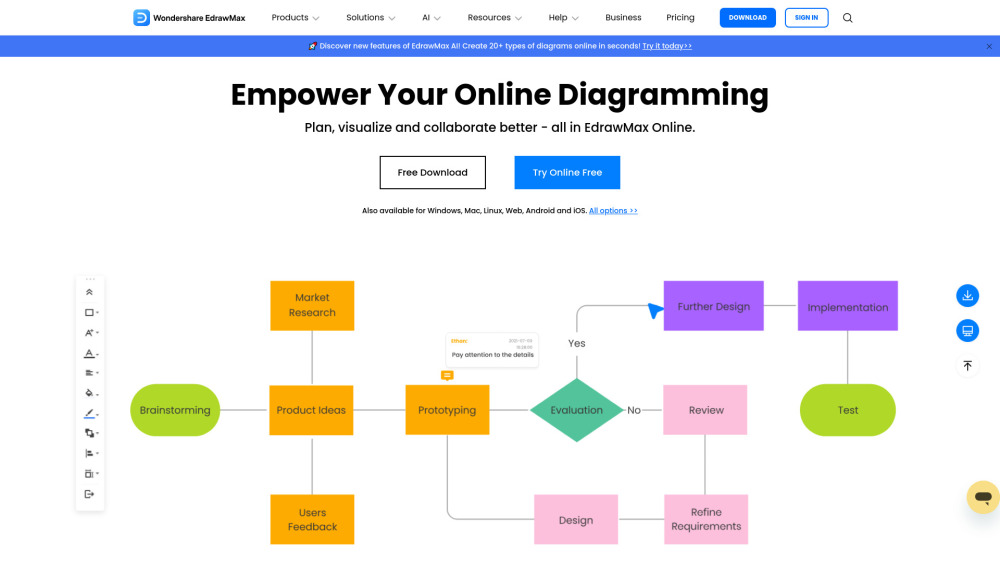
أنشئ رسومات رائعة مع أداة إنشاء المخططات عبر الإنترنت
ارتق بمشاريعك وعروضك التقديمية مع أداة إنشاء المخططات السهلة الاستخدام لدينا. صمم رسومات بجودة احترافية بسهولة، من خلال قوالب قابلة للتخصيص وأدوات سهلة الاستخدام. سواء كنت بحاجة إلى مخططات انسيابية، أو خرائط ذهنية، أو مخططات تنظيمية، فإن منصتنا تمكّنك من إيصال أفكارك بوضوح وفاعلية. ابدأ في تصميم مخططات مدهشة اليوم!
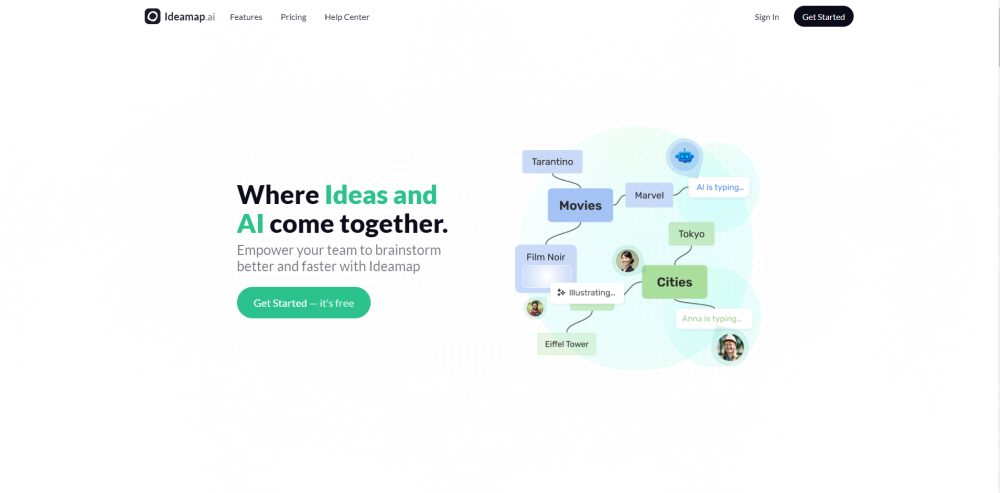
أطلق إبداعك من خلال تسخير قوة الذكاء الاصطناعي في العصف الذهني البصري. اكتشف طرقًا مبتكرة لتوليد أفكار جديدة وتعزيز عملية إبداعك من خلال التكنولوجيا المتقدمة.

عزّز طابعاتك ثلاثية الأبعاد OctoPrint وKlipper من خلال فتح الوصول عن بُعد مجانًا والاستفادة من تقنية الذكاء الاصطناعي لاكتشاف الأعطال.

هل أنت مستخدم لموقع Webflow وترغب في زيادة رؤية موقعك الإلكتروني؟ تطبيق تحسين محركات البحث (SEO) لدينا مصمم خصيصًا لك. مع أدوات قوية وميزات سهلة الاستخدام، يجعل تحسين موقعك لمحركات البحث أسهل من أي وقت مضى. عزز وجودك على الإنترنت، واجذب المزيد من الزيارات، وارتقِ بترتيبك في نتائج البحث بلا جهد. انضم إلى مجتمع مستخدمي Webflow المتزايد الذين يحولون مواقعهم الإلكترونية بفضل حلولنا في تحسين محركات البحث!
Find AI tools in YBX
Related Articles
Refresh Articles