أعلنت OpenAI عن إطلاق وضع الصوت GPT-4o لمستخدمي ChatGPT Plus، مما يعزز المحادثات الطبيعية في الوقت الحقيقي.
Most people like
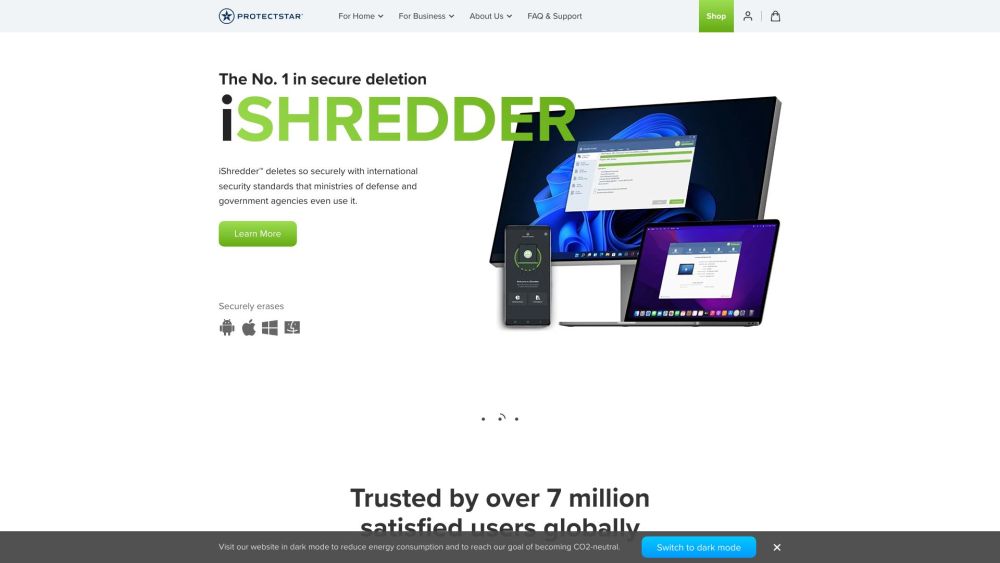
اكتشف قوة محو البيانات، إلى جانب الذكاء الاصطناعي المتقدم لمكافحة الفيروسات وذكاء الحماية من الجدران النارية، المصمم لتوفير حلول أمان متينة. احمِ ممتلكاتك الرقمية مع هذه التقنيات المتطورة التي تضمن بقاء معلوماتك محمية ووجودك على الإنترنت آمنًا.
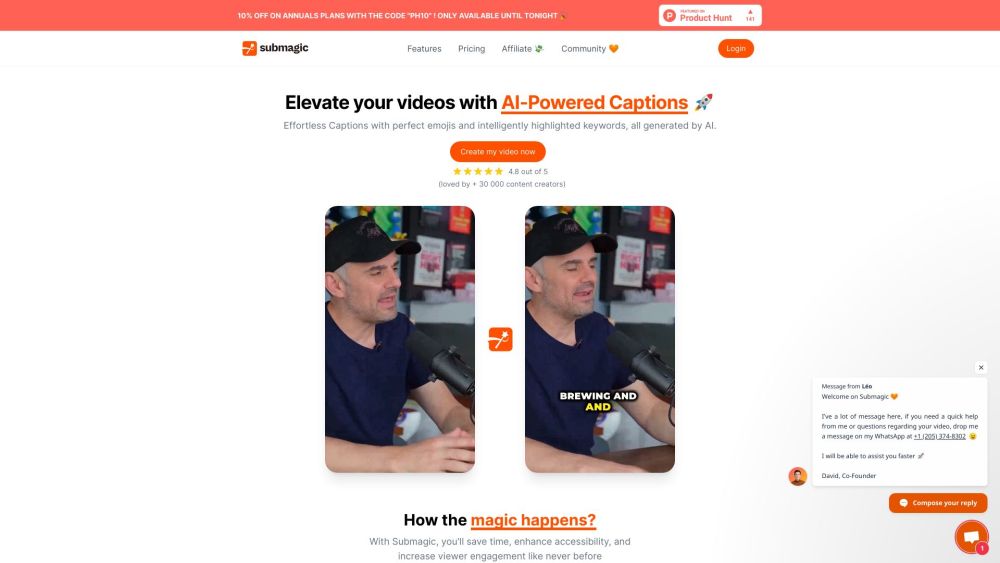
قم بإنشاء عناوين جذابة مليئة بالرموز التعبيرية لمحتواك القصير. تفاعل مع جمهورك واجعل منشوراتك تبرز!

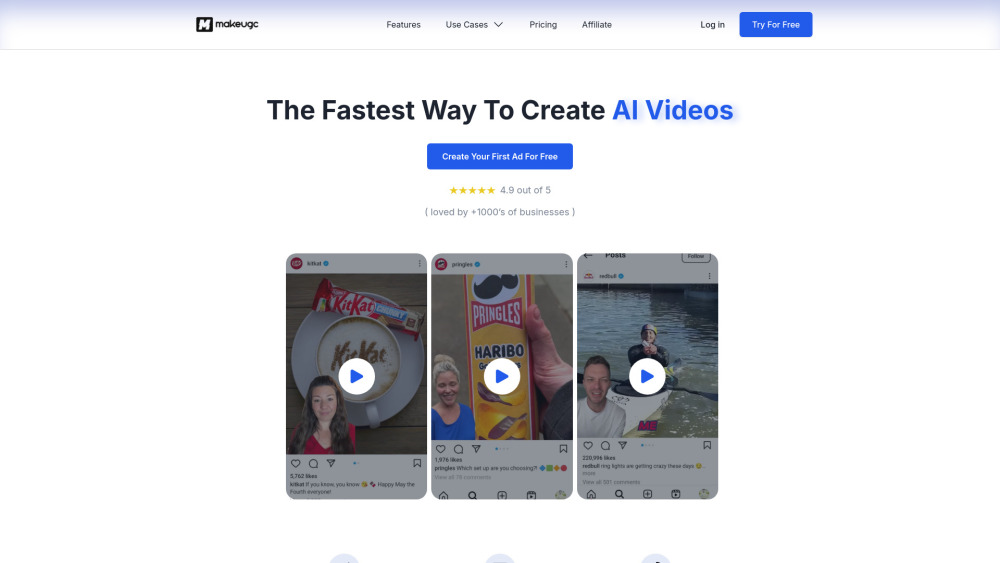
نقدم لكم منصة مبتكرة تعتمد على الذكاء الاصطناعي، مصممة لإنشاء مقاطع فيديو محتوى من قبل المستخدمين بسرعة. حول أفكارك إلى مقاطع فيديو جذابة في دقائق، مما يسهل عملية إنشاء المحتوى للأفراد والعلامات التجارية على حد سواء. سواء كنت مؤثرًا على وسائل التواصل الاجتماعي أو مالكًا لمشروع، تتيح لك منصتنا إنتاج مقاطع فيديو عالية الجودة بسهولة تأسر جمهورك. اكتشف مستقبل إنشاء الفيديوهات اليوم!
Find AI tools in YBX
Related Articles
Refresh Articles