معهد ماساتشوستس للتكنولوجيا وكوهير يتعاونان لإطلاق منصة لتتبع وتصنيف مجموعات بيانات الذكاء الاصطناعي المدققة.
Most people like

أنشئ سير ذاتية احترافية بسهولة مع صانع السير الذاتية المدعوم بالذكاء الاصطناعي من CVBee.ai في دقائق معدودة. احصل على دفعة في طلبات التوظيف وطور آفاق حياتك المهنية الآن!
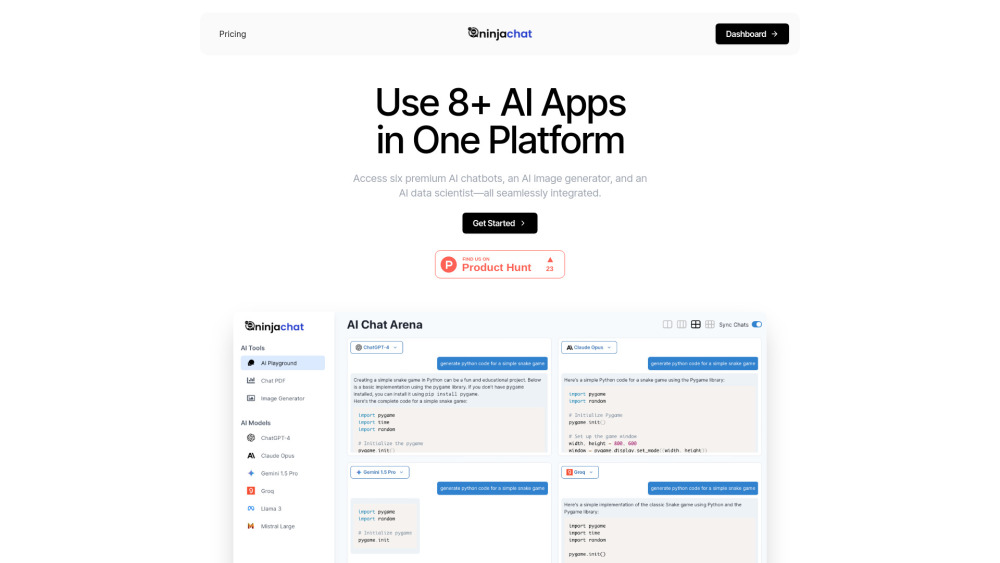
نقدم لكم منصة متطورة للدردشة الذكية مزودة بمجموعة من الأدوات المتكاملة لتعزيز تجربة المستخدم وزيادة التفاعل. حول تفاعلات العملاء لديك وسهل التواصل بسهولة مع حلولنا الذكية القوية.
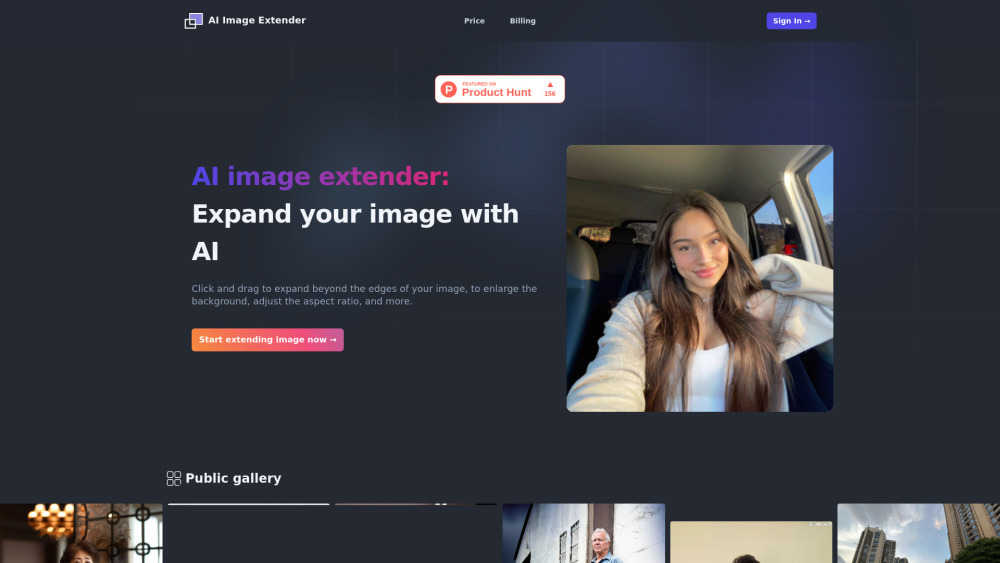
في عالم اليوم المدفوع بالصور، لم تكن الحاجة إلى الصور عالية الجودة بهذه القوة من قبل. إدخال أداة توسيع الصور بالذكاء الاصطناعي—تقنية مبتكرة تعزز وتكبر صورك مع الحفاظ على تفاصيل ووضوح مذهلين. سواء كنت بحاجة إلى تحسين صورة شخصية أو تحسين الصور للاستخدام المهني، فإن هذه الأداة التحولية تستفيد من خوارزميات الذكاء الاصطناعي المتقدمة لتحقيق نتائج مذهلة. اكتشف كيف أن أداة توسيع الصور بالذكاء الاصطناعي تحدث ثورة في طريقة إنشاء المحتوى البصري ومشاركته، مما يجعل من السهل أكثر من أي وقت مضى رفع صورك إلى آفاق جديدة.
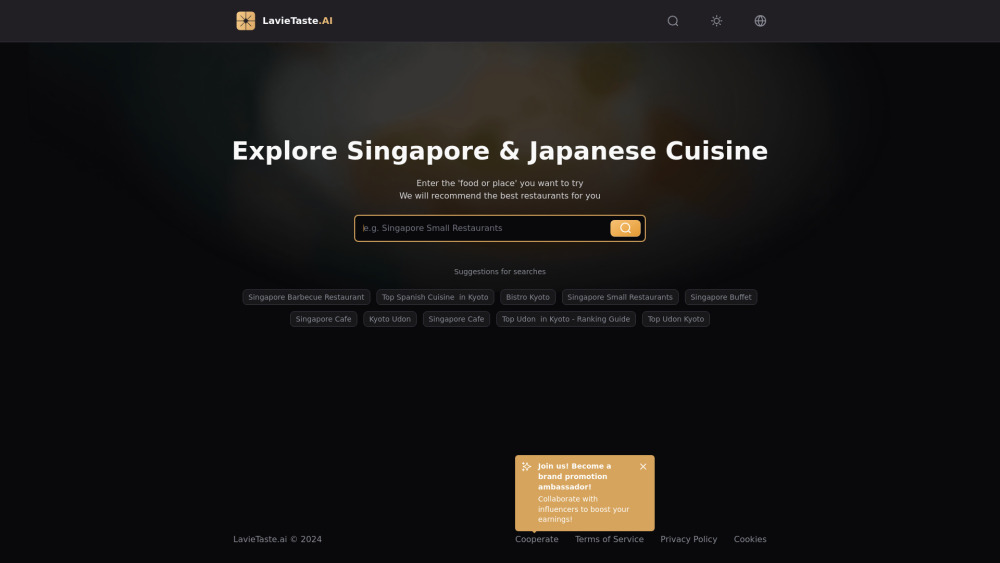
اكتشف توصيات المطاعم المدعومة بالذكاء الاصطناعي: دليلك الشامل للمأكولات السنغافورية واليابانية.
استمتع بعالم المأكولات الشهية السنغافورية واليابانية مع تكنولوجيا الذكاء الاصطناعي المتطورة التي تقدم لك اقتراحات تناول الطعام المصممة خصيصًا لك. سواء كنت تتوق إلى الأطباق المحلية الشهية أو النكهات اليابانية الأصيلة، اعثر على المطعم المثالي لإرضاء ذوقك!
Find AI tools in YBX
Related Articles
Refresh Articles