ميتا تطلق نموذج مترجم LLM: تعزيز مهارات البرمجة الذكية لتحسين كفاءة الكود
Most people like

ارتقِ برحلة صحتك مع مدرب شخصي مدعوم بالذكاء الاصطناعي
اختبر نهجًا مخصصًا للياقة البدنية والصحة كما لم يحدث من قبل. يقوم مدربنا الشخصي المدعوم بالذكاء الاصطناعي بتخصيص خطط التمارين الصحية لتناسب احتياجاتك الفريدة، مما يضمن رحلة تحقق أقصى النتائج وتعزز من رفاهيتك العامة. اكتشف مستقبل التدريب الصحي اليوم!
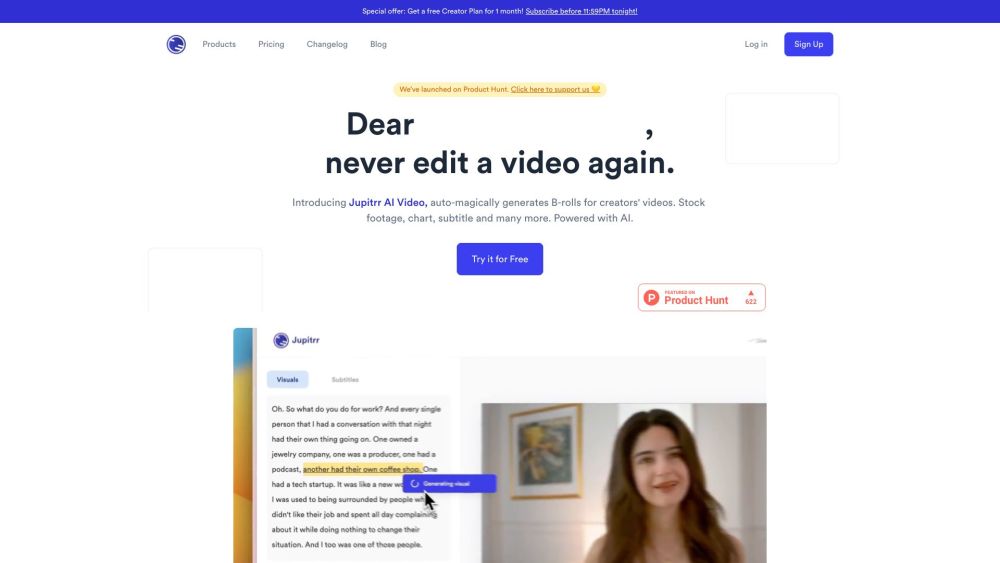
أنشئ مقاطع B-roll مذهلة بسهولة مع صانع الفيديو المدعوم بالذكاء الصناعي. مصمم لتبسيط عملية إنتاج الفيديو الخاصة بك، يقوم هذا الأداة المبتكرة تلقائيًا بتوليد محتوى B-roll عالي الجودة، مما يوفر لك الوقت ويعزز التأثير العام لمقاطعك. ارتقِ بسرد القصص لديك وزد من تفاعل الجمهور من خلال دمج بصري جذاب بسلاسة.
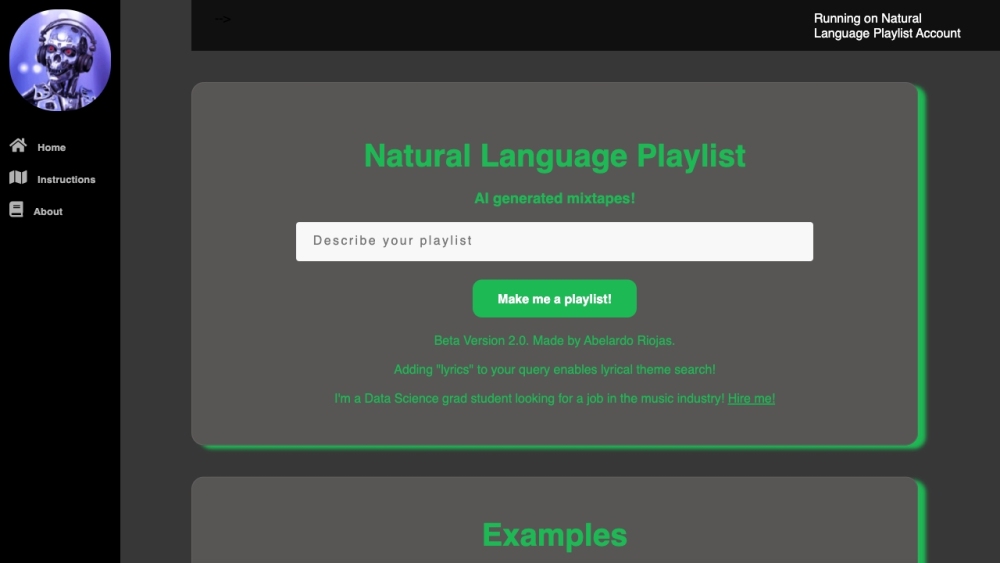
اكتشف منصة مبتكرة للذكاء الاصطناعي تتيح لك إنشاء خلطات موسيقية مخصصة بناءً على أوصافك الفريدة بلغة طبيعية. هذه التقنية المتطورة تحول كلماتك إلى تجربة موسيقية مصممة خصيصًا لك.
تقدم داتاتراك رؤى بيانات قيمة مصممة خصيصًا لشركات الشحن، مما يمكّنها من اتخاذ قرارات مستنيرة تعزز كفاءة التشغيل وتدعم النمو.
Find AI tools in YBX
Related Articles
Refresh Articles