Kimi Platform präsentiert die Dunkle Seite des Mondes: Öffentliche Beta für Context Caching gestartet, senkt Kosten für Langtext-Modelle.
Most people like
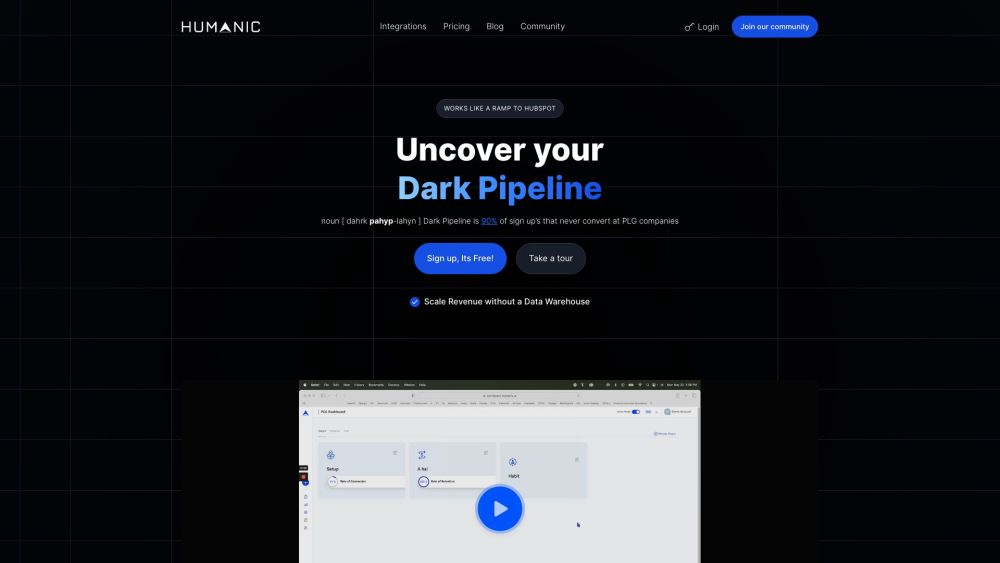
Humanic PLG CRM ist eine spezialisierte Software, die ausschließlich für Product-Led Growth (PLG) Unternehmen entwickelt wurde. Sie ermöglicht es Unternehmen, ihre wertvollsten Nutzer zu identifizieren, zu konvertieren und zu binden, indem sie nahtlos mit bestehenden Sales-Led CRM-Systemen integriert wird. Diese innovative Lösung verbessert die Nutzerinteraktion und fördert das Wachstum, wodurch sie ein unverzichtbares Werkzeug für PLG-Strategien wird.
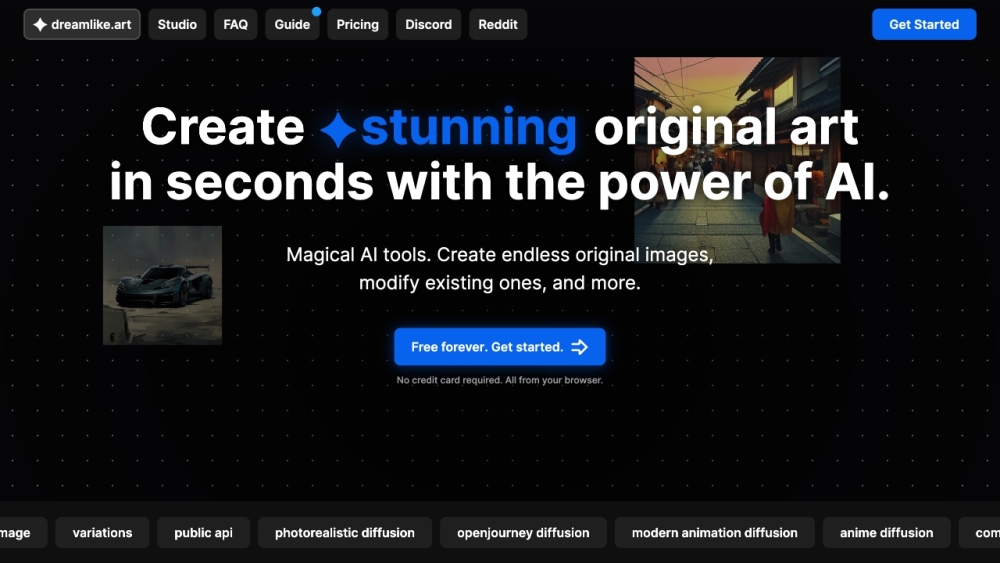
Verwandle deine kreative Vision in atemberaubende Kunstwerke in nur wenigen Sekunden mit Stable Diffusion, dem kostenlosen KI-Kunstgenerator und -Macher, der für Künstler und Enthusiasten gleichermaßen entwickelt wurde.
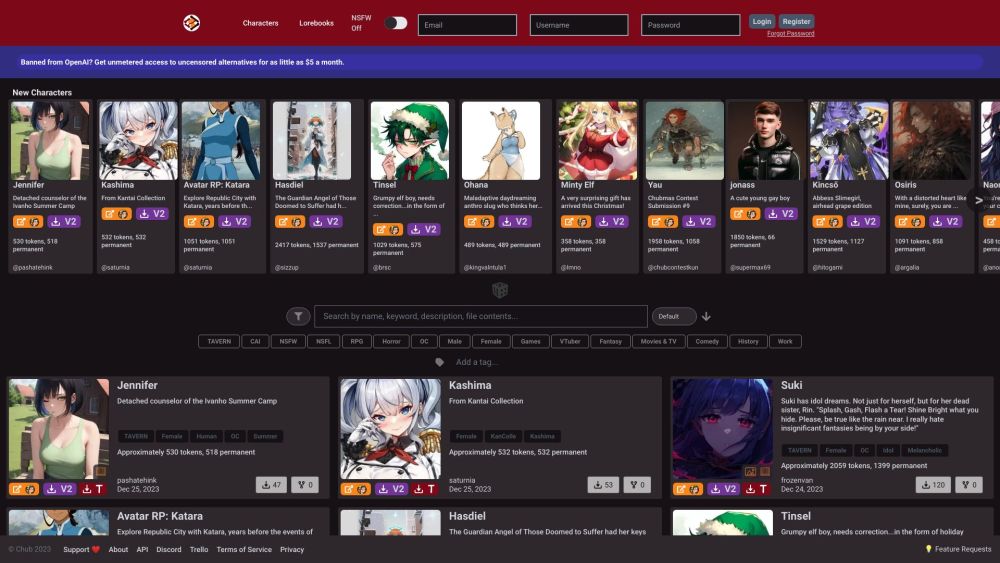
Entfalten Sie das volle Potenzial Ihrer Sprachmodelle, indem Sie das Charaktermanagement effektiv verwalten und zusammenarbeiten. Ob Sie interaktive Geschichten erstellen, einzigartige Personas designen oder KI trainieren, um verschiedene Stimmen zu verstehen – das Beherrschen des Charaktermanagements ist entscheidend, um realistische und fesselnde Ergebnisse zu erzielen.

Entfernen Sie mühelos unerwünschte Objekte aus Ihren Fotos mit unseren benutzerfreundlichen Techniken.
Find AI tools in YBX
Related Articles
Refresh Articles