Kontroversen um kostenloses KI-Bilddatenset nach Entfernung von Bildern Kindesmissbrauchs
Most people like

In der heutigen schnelllebigen Finanzlandschaft revolutionieren KI-gesteuerte Technologien die Art und Weise, wie Investoren Chancen identifizieren und mit Unternehmungen zusammenarbeiten. Durch den Einsatz fortschrittlicher Algorithmen und Datenanalysen verbessern diese Lösungen vorausschauende Anlagestrategien, die es ermöglichen, klügere und informiertere Entscheidungen zu treffen. Diese Innovation rationalisiert nicht nur den Investitionsprozess, sondern fördert auch bedeutsame Verbindungen zwischen Investoren und Startups und ebnet den Weg für Wachstum und Erfolg in aufstrebenden Märkten. Entdecken Sie, wie KI die Welt der vorausschauenden Investitionen und der Unternehmenszuordnung transformiert und eine dynamische Synergie zwischen Kapital und Innovation schafft.
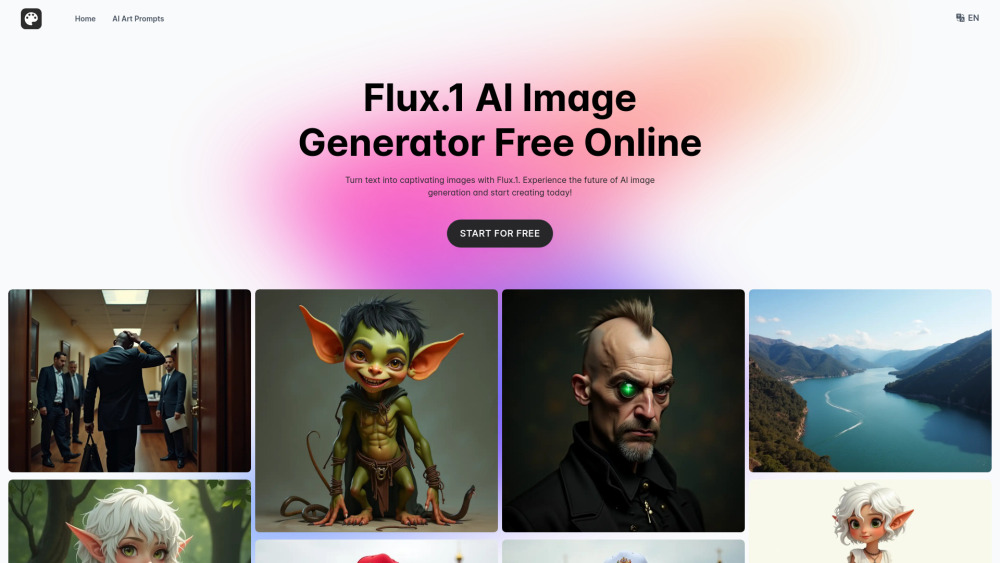
Erstellen Sie atemberaubende, hochwertige Bilder aus Text mit der Kraft der KI. Verwandeln Sie Ihre Worte mühelos in visuell fesselnde Kunst.
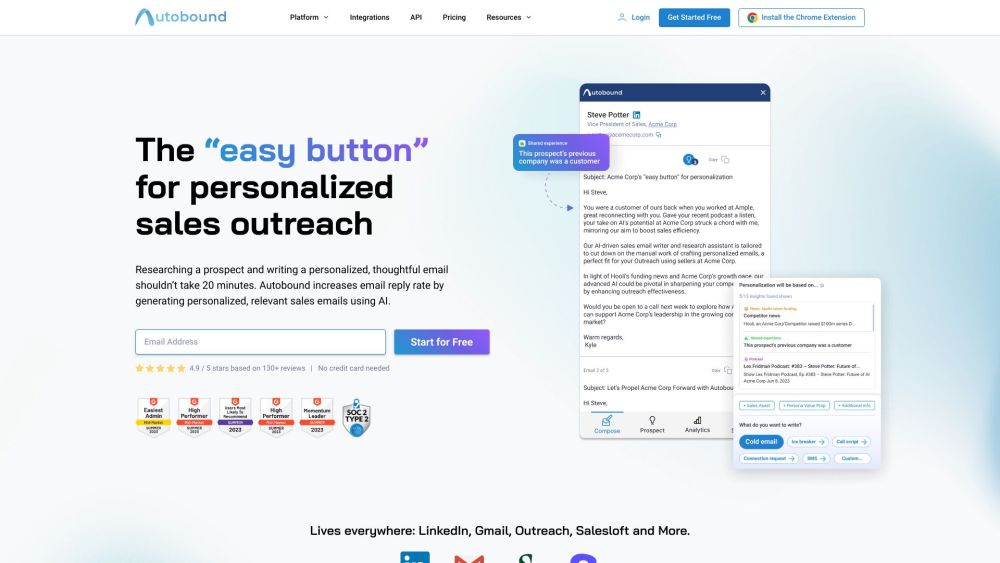
Wir präsentieren unsere KI-gestützte Plattform, die für hyper-personalisierte Ansprache entwickelt wurde. Dieses innovative Tool nutzt fortschrittliche Algorithmen, um Kommunikationsstrategien maßzuschneidern und sicherzustellen, dass jede Interaktion bei Ihrem Publikum Anklang findet. Erleben Sie die Zukunft des Marketings, während wir die Art und Weise transformieren, wie Sie mit Kunden in Kontakt treten, und jede Nachricht relevanter und wirkungsvoller gestalten. Steigern Sie Ihre Engagement-Bemühungen und fördern Sie Konversionen mit unserer hochmodernen Technologie.
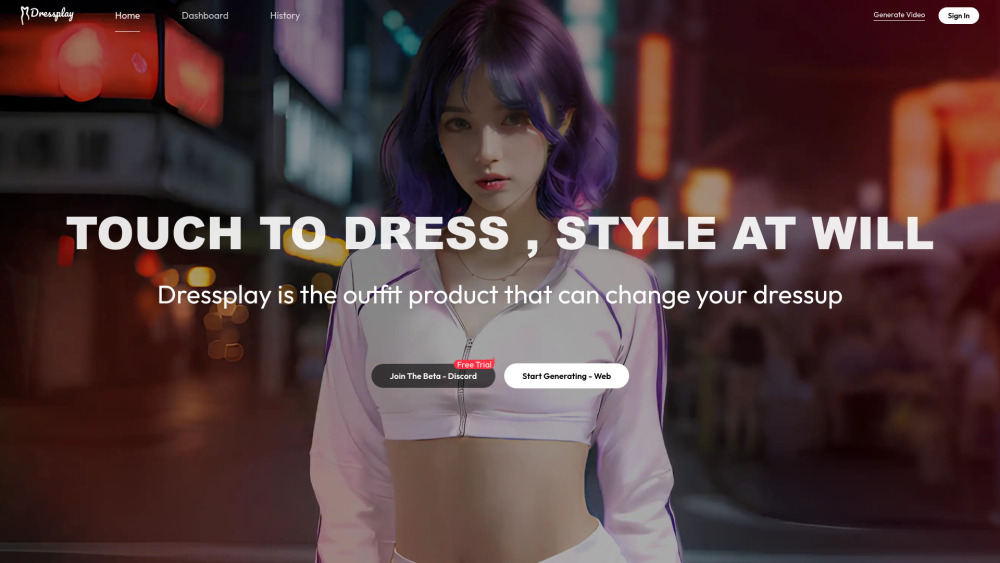
Präsentation von DressPlay – einer innovativen KI-Kleiderwechsel-App, die sowohl für Modebegeisterte als auch für E-Commerce-Unternehmen entwickelt wurde. Ob Sie neue Stile ausprobieren oder Ihr Online-Einkaufserlebnis verbessern möchten, DressPlay bietet eine nahtlose Möglichkeit, Ihren Kleiderschrank mit nur einem Klick zu verwandeln.
Find AI tools in YBX
Related Articles
Refresh Articles